Nvidia has taken the wraps off its next generation CUDA GPU architecture, Fermi. Engineered from the ground-up, the company says Fermi delivers breakthroughs in both graphics and GPU computing. Parallel Computing Research Laboratory director Dave Patterson believes Nvidia has taken a leap toward making GPUs attractive for a broader class of programs, and thinks the company's latest technology will stand as a significant milestone.
Showcased at Nvidia's GPU conference in California today, Oak Ridge National Laboratory already plans to use Fermi in a new supercomputer, and the architecture garnered the support of various organizations, including Bloomberg, Cray, Dell, HP, IBM and Microsoft. Nvidia's next-gen chip features a slew of new "must-have" technologies like ECC, 512 CUDA Cores with the new IEEE 754-2008 floating-point standard, and 8x the peak double precision arithmetic performance over Nvidia's last generation GPU.
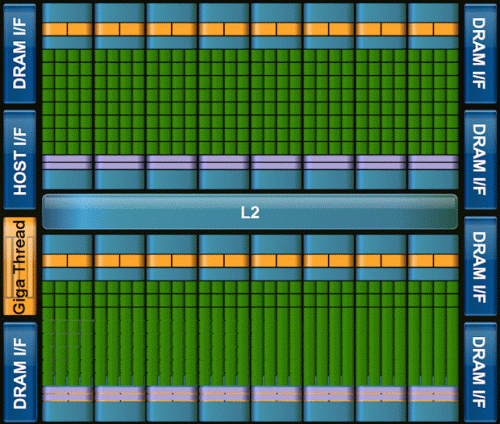
Other features include Nvidia Parallel DataCache, Nvidia GigaThread Engine, and Nexus. Technical whitepapers and more information can be found on Fermi's page. The Tech Report and Real World Technologies each have detailed write-ups on Fermi, which include some speculative performance comparisons on AMD's next-generation GPU.