The big picture: One of the most undisputed beneficiaries of the generative AI phenomenon has been the GPU, a chip that first made its mark as a graphics accelerator for gaming. As it happens, GPUs have proven remarkably adept at facilitating and enhancing the process of training large foundation models, and executing AI inferencing workloads.

Up until now, the big winner in the generative AI GPU game has been Nvidia, thanks to a combination of strong hardware and a large installed base of CUDA software tools. However, at an event in San Francisco this week, AMD came out with new GPU and CPU hardware and important new software partnerships and updates. Together, AMD believes these developments will allow it to secure a larger share of a datacenter AI accelerator market it predicts will reach $150 billion by 2027.
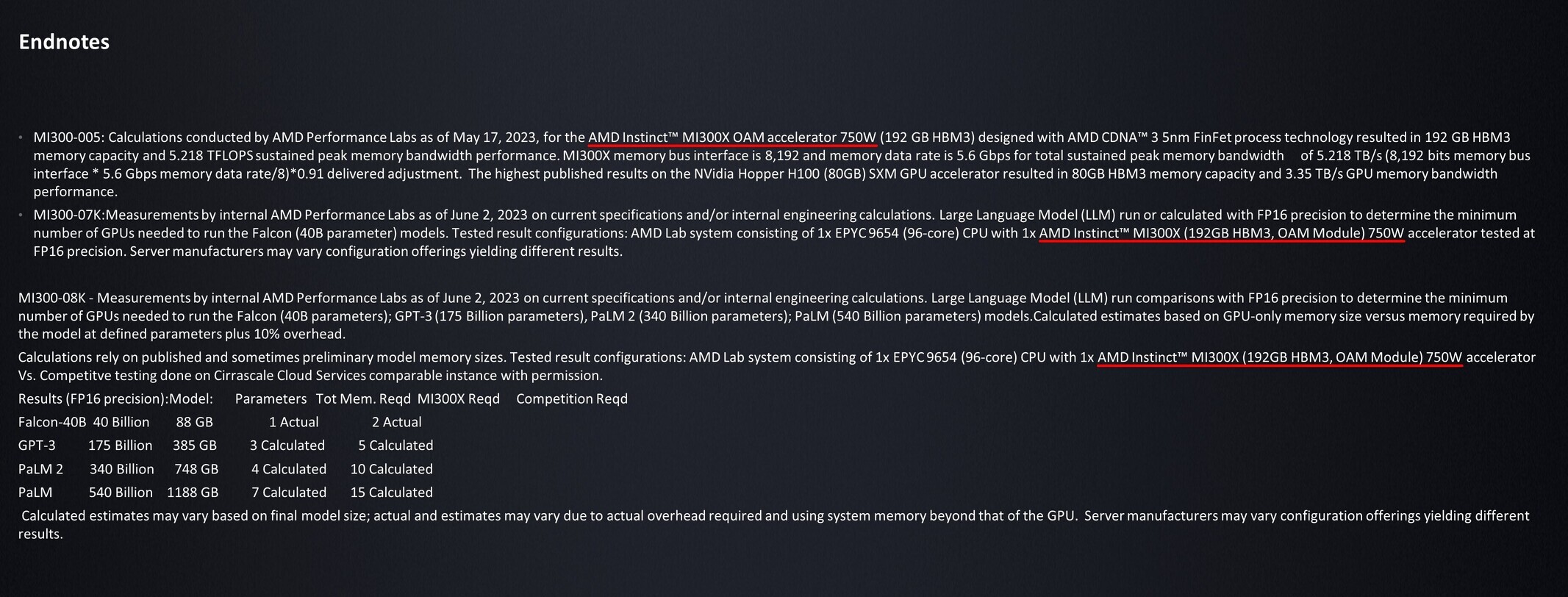
AMD introduced the new Instinct MI300X chip as a dedicated generative AI accelerator. It leverages the same basic chiplet design as the previously announced Instinct MI300A (which AMD is now sampling), but the MI300X substitutes the 24 Zen 4 CPU cores in the MI300A with additional CDNA3 GPU cores and High Bandwidth Memory (HBM).

Indeed, this new chip – with a total of 153 billion transistors – boasts 192 GB of HBM and offers 5.2 TB/second of memory bandwidth. These numbers represent a 2.4x increase in memory capacity and a 1.6x enhancement in throughput compared to Nvidia's current H100 accelerator. Although these figures may be overwhelming for most applications, large language models (LLMs) run most efficiently in memory, indicating this should translate to solid real-world performance when the chip begins sampling in the third quarter of this year.
On the software front, AMD made several significant announcements. Firstly, the company detailed the latest version of its ROCm platform for AI software development, ROCm 5. This comprises low-level libraries, compilers, development tools, and a runtime that lets AI-related workloads run natively on AMD's Instinct line of GPU accelerators. This serves as the foundation for AI development frameworks like PyTorch, TensorFlow, and ONNX. Moreover, a new partnership with the PyTorch Foundation emerged at AMD's event. From PyTorch 2.0 onwards, any AI models or applications developed with PyTorch will run natively on AMD Instinct accelerators that have been upgraded to support ROCm 5.4.2.
This development is significant as many AI models are built with PyTorch and, until this announcement, most could only run on Nvidia's GPUs. Now, developers and major cloud computing providers can opt to use AMD Instinct accelerators directly or replace Nvidia accelerators with AMD ones.
Another major software announcement involved Hugging Face, which has rapidly become the go-to site for open-source AI models. As part of their new partnership, Hugging Face will collaborate with AMD to ensure compatibility of existing and new open-source models posted on its site with Instinct accelerators. They also plan to work on compatibility across other AMD processors, including Epyc and Ryzen CPUs, Radeon GPUs, Alveo DPUs, and Versal FPGAs (or adaptive processors, as AMD refers to them). This should help position AMD as a viable alternative to Nvidia in several AI datacenter environments.

On the datacenter CPU front, AMD announced their new "Bergamo" and "Genoa X" versions of their fourth-generation Epyc processors, and hinted at another version named "Sienna" to be announced later this year. Bergamo is optimized for cloud computing workloads, featuring a new smaller Zen4c core and accommodating more of these smaller cores onto the chip (up to 128). The refined architecture facilitates operations such as running more containers simultaneously, leading to impressive benchmarks that partners including AWS, Azure, and Meta were keen to discuss.
The Genoa X model combines AMD's 3D V-Cache technology, first introduced with their third-generation "Milan" series, with the fourth-generation Genoa CPU design. It's optimized for technical and high-performance computing (HPC) workloads that require more and faster on-die cache memories.

These CPU developments, as well as variations on the Instinct MI300 accelerator, reflect AMD's growing diversity of designs optimized for specific applications. All these can leverage key AMD technologies, including their chiplet-based design and the Infinity Fabric interconnect technology. It's a prime example of how forward-looking designs can significantly influence overall strategies.
AMD also unveiled the Instinct Platform at their event, which, like Nvidia's similar offering, integrates eight of AMD's GPU-based accelerators (MI300Xs) into a single, compact hardware design.

To be clear, Nvidia still maintains a significant lead in generative AI training and holds a strong position in inferencing. H owever, once these new accelerators and software partnerships begin to influence the market, they could make a notable difference for AMD. While many companies appreciate what Nvidia has achieved for generative AI, no one relishes a market dominated by a single entity. Consequently, several companies will likely welcome AMD's emergence as a strong alternative in this sector.
On the datacenter CPU front, AMD has already established itself as a solid alternative to Intel. It's not difficult to imagine the company developing a similar profile in datacenter AI accelerators. While the journey won't be easy, it's bound to make things more exciting.
https://www.techspot.com/news/99071-amd-take-ai-instinct-mi300x-combines-cpu-gpu.html