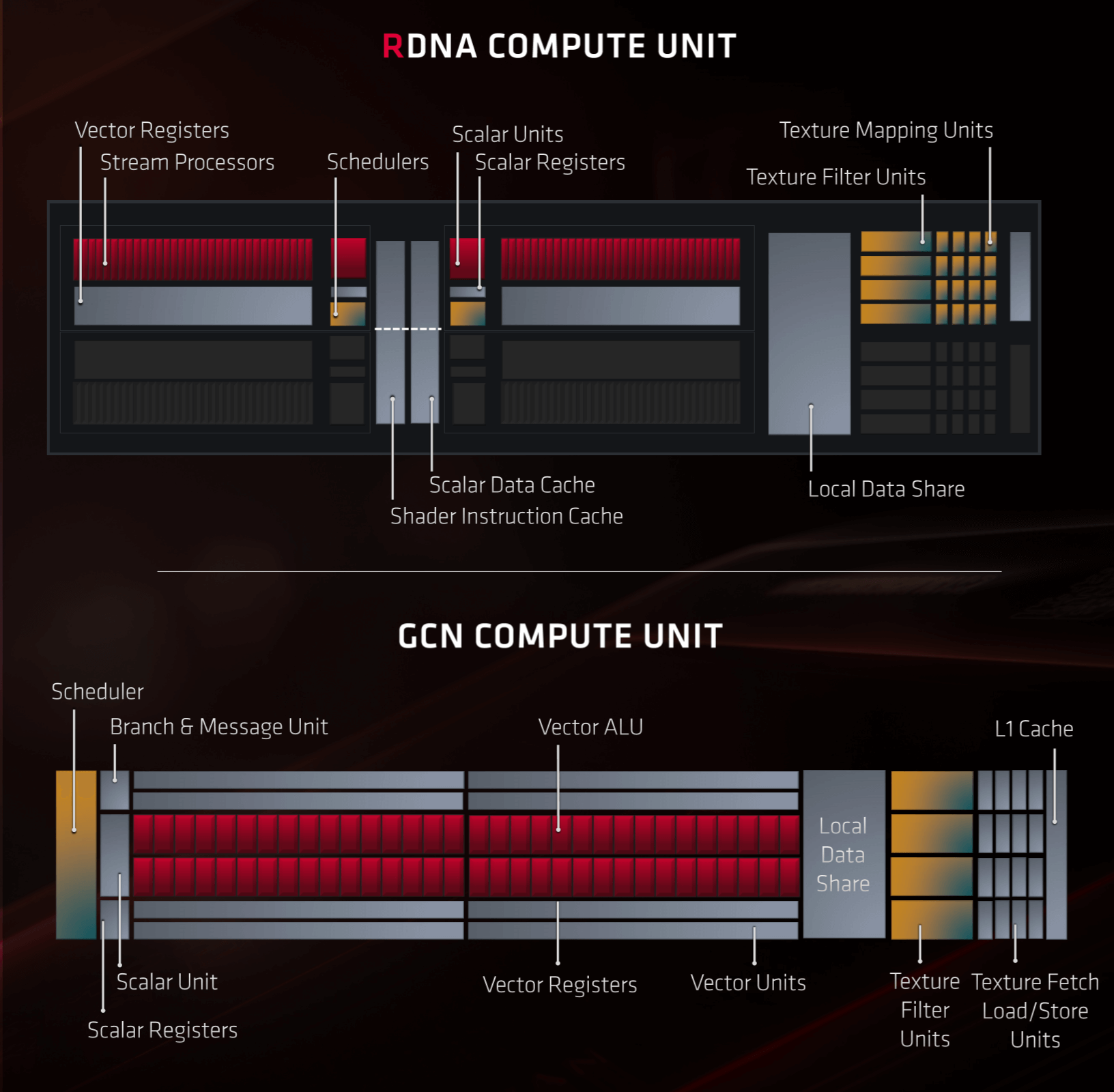
...
The idea that such complex technology is available to people, but all they know about it is the brand, and what it cost to get it. No passion at all imo.
...
If I may continue your off topic for a moment ...
Yes ... no passion - good way of putting it ...
I see the issue as caused by "alignment"; a lazy-butt replacement for knowledge seeking and critical thinking.
People tend to "align" themselves to (or against) a brand, an ideology, or say, a political party, etc.
However, that "alignment" for some becomes
so strong that any information that may appear to threaten their "justification" for that alignment, is immediately denied without thought or logic. It becomes a program that runs automatically with no brain needed.
This feeds into the nature of human laziness -- alignments don't take any energy, don't require any thought, reasoning, critical thinking -- all they need is some injected emotion here and there. Research, education, learning, truth finding, sense-making and objectivity all take work, and let's face it we live in the age of lazy phone zombies that have a 5 second attention span.
We
all have alignments to some extent - this is
normal and to be
expected, but its the
strength of that alignment that determines the level of blindness and "laziness" inflicted on an individual.
My problem is that I give people too much benefit of the doubt and find myself disappointed with people outright, although I do try to keep things light if interacting in such a way to point it out (I've ticked off a few people on this forum already in a short amount of time without even trying, just by pointing out objective facts).
People with strong alignments tend to get all bent out of shape when you force facts or critical considerations on them that they perceive as threatening to the strength of their alignments. They don't consciously do this - its a program that runs automatically ...
Anyway, back to topic ....