TL;DR: Encodec is a next-generation audio codec based on a complex neural network design, a system that can squeeze a lot of audio juice into minimal storage space. The codec would work for Metaverse experiences and optimizing mobile phone calls.

Thanks to its high efficiency and integrated support by iconic products like the everlasting Winamp player, the MP3 codec became the de-facto standard for sharing audio files on the internet during the Nineties and beyond. Now, a new codec wants to make history again by offering even more extreme gains in efficiency and bandwidth saving. The secret is an AI algorithm capable of "hypercompressing" audio streams.
Meta researchers conceptualized Encodec as a potential solution for supporting "current and future" high-quality experiences in the metaverse. The new technology is a neural network trained to "push the boundaries of what's possible" in audio compression for online applications. The system can achieve "an approximate 10x compression rate" compared to the MP3 standard.
Meta trained the AI "end to end" to achieve a specific target size after compression. Encodec can squeeze a 64 Kbps MP3 data stream into 6 Kbps, which means it needs just 6,144 bytes (yes, bytes) to keep the same quality as the original. The researchers say the codec can compress 48 kHz stereo audio samples for speech — an industry first.
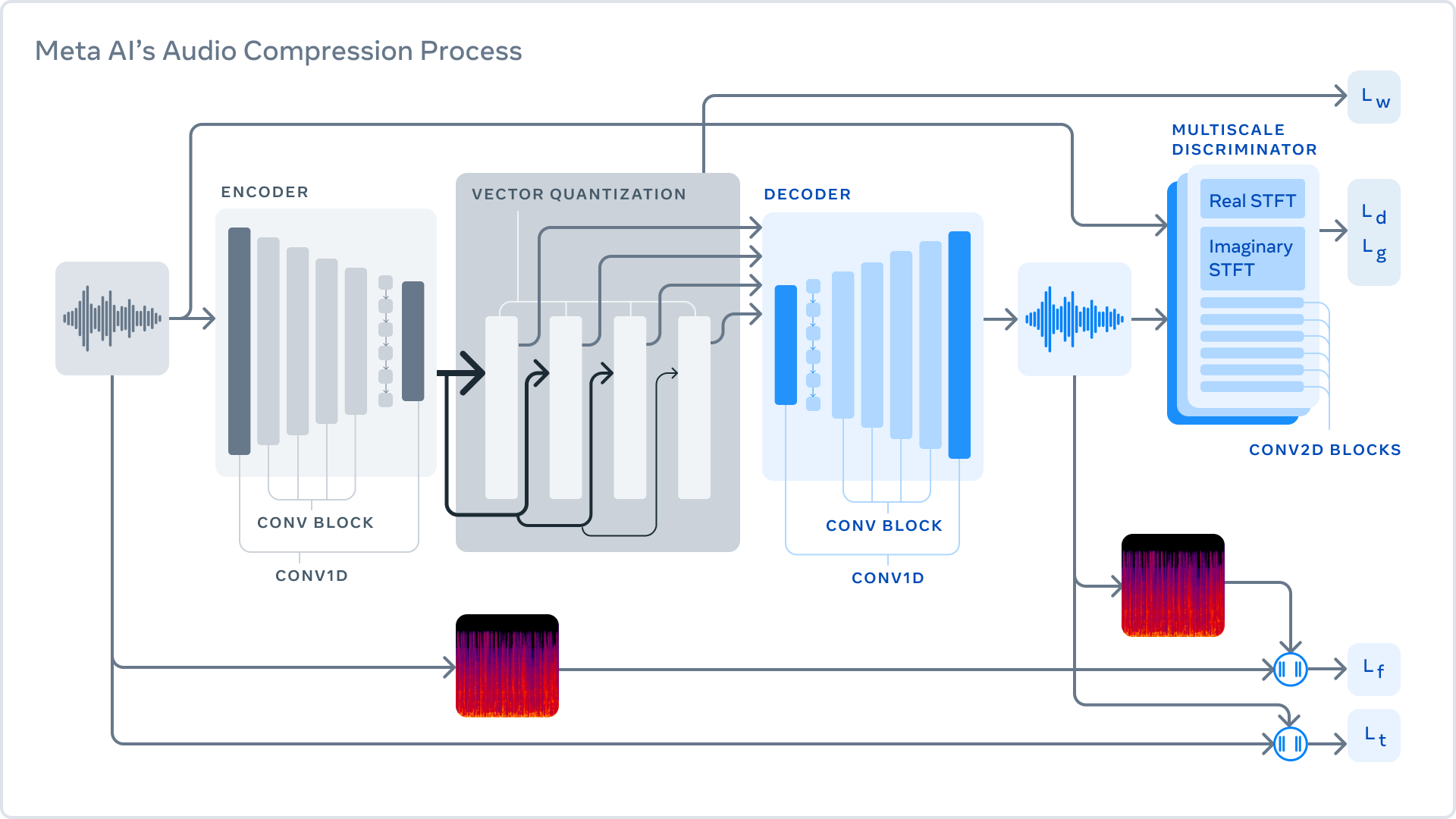
The AI-based approach can "compress and decompress audio in real-time to state-of-the-art size reductions," with potentially incredible results, as seen in the sample shared on Meta's AI blog. Classic codecs like MP3, Opus, or EVS decompose the signal between different frequencies and encode as efficiently as possible leveraging psychoacoustics (the study of human sound perception). Encodec's methods are based on a complex design comprising three parts: the encoder, the quantizer, and the decoder.
The encoder takes uncompressed data and turns it into a higher dimensional and lower frame rate representation. The quantizer compresses this stream to the target size while retaining the most vital information to rebuild the original signal. Finally, the decoder turns the compressed signal into a waveform that is "as similar as possible to the original."
Encodec's machine learning model identifies audio changes that are imperceptible to humans, using discriminators to improve the perceived quality of the generated sounds. Meta described this process as a "cat-and-mouse game," with the discriminator differentiating between the original and reconstructed samples. The final result is superior audio compression in low-bitrate speech (1.5 kbps to 12 kbps).
Encodec can encode and decode audio data in real-time on a single CPU core, Meta said, and it still offers many areas of improvement for even smaller file sizes. Beyond supporting next-gen Metaverse experiences on today's internet connections, the new model could potentially guarantee higher-quality phone calls in areas where mobile coverage is anything but optimal.
https://www.techspot.com/news/96528-encodec-facebook-ai-assisted-audio-codec-rich-metaverse.html
