Bottom line: More and more AI companies say their models can reason. Two recent studies say otherwise. When asked to show their logic, most models flub the task – proving they're not reasoning so much as rehashing patterns. The result: confident answers, but not intelligent ones.

Apple researchers have uncovered a key weakness in today's most hyped AI systems – they falter at solving puzzles that require step-by-step reasoning. In a new paper, the team tested several leading models on the Tower of Hanoi, an age-old logic puzzle, and found that performance collapsed as complexity increased.
The Tower of Hanoi puzzle is simple: move a stack of disks from one peg to another while following rules about order and disk size. For humans, it's a classic test of planning and recursive logic. For language models trained to predict the next token, the challenge lies in applying fixed constraints across multiple steps without losing track of the goal.
Apple's researchers didn't just ask the models to solve the puzzle – they asked them to explain their steps. While most handled two or three disks, their logic unraveled as the disk count rose. Models misstated rules, contradicted earlier steps, or confidently made invalid moves – even with chain-of-thought prompts. In short, they weren't reasoning – they were guessing.
These findings echo a study from April when researchers at ETH Zurich and INSAIT tested top AI models on problems from the 2025 USA Mathematical Olympiad – a competition requiring full written proofs. Out of nearly 200 attempts, none produced a perfect solution. One of the stronger performers, Google's Gemini 2.5 Pro, earned 24 percent of the total points – not by solving 24 percent of problems, but through partial credits on each attempt. OpenAI's o3-mini barely cleared 2 percent.
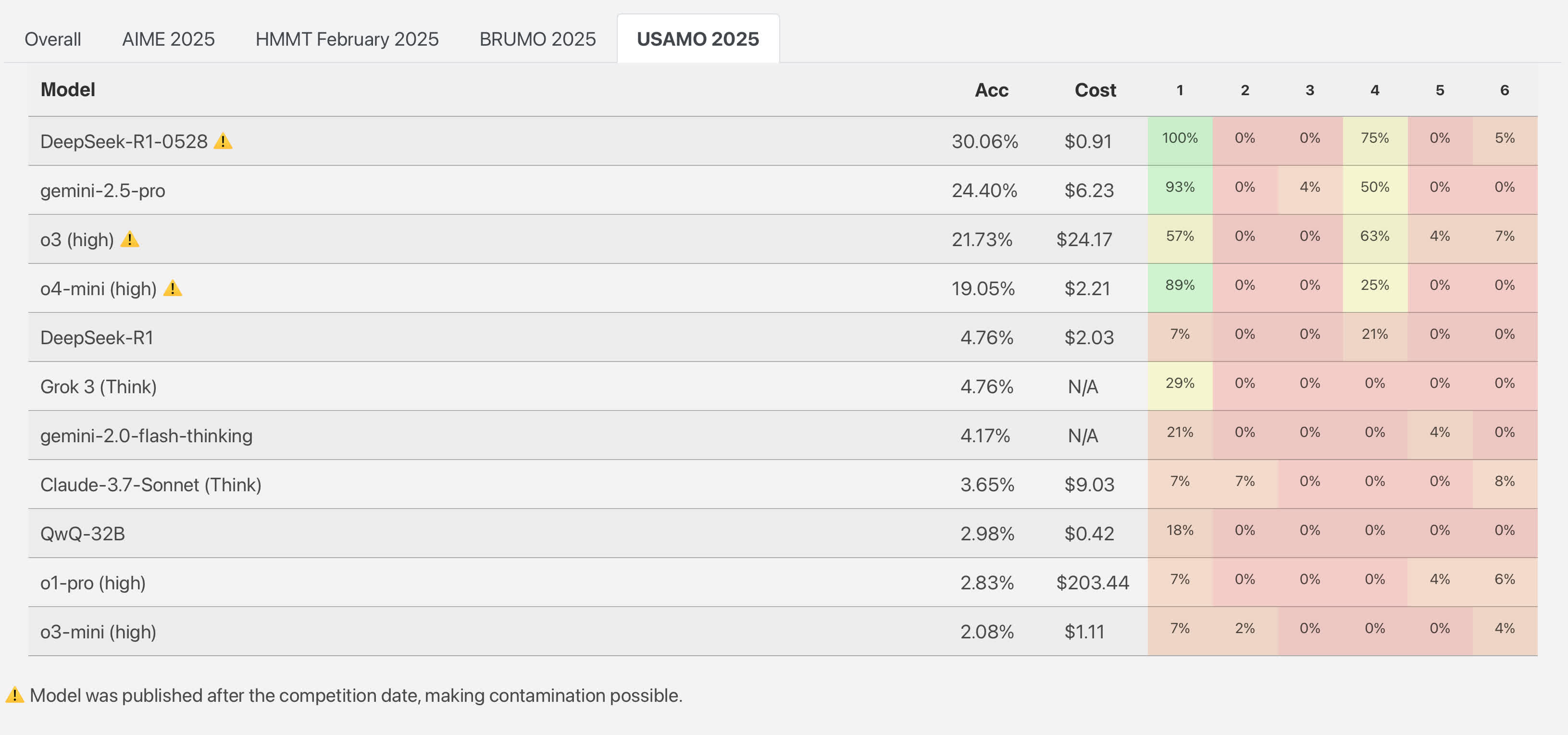
The models didn't just miss answers – they made basic errors, skipped steps, and contradicted themselves while sounding confident. In one problem, a model started strong but excluded valid cases without explanation. Others invented constraints based on training quirks, such as always boxing final answers – even when it didn't fit the context.
Gary Marcus, a longtime critic of AI hype, called Apple's findings "pretty devastating to large language models."
"It is truly embarrassing that LLMs cannot reliably solve Hanoi," he wrote. "If you can't use a billion dollar AI system to solve a problem that Herb Simon one of the actual 'godfathers of AI,' solved with AI in 1957, and that first semester AI students solve routinely, the chances that models like Claude or o3 are going to reach AGI seem truly remote."
Even when given explicit algorithms, model performance didn't improve. The study's co-lead Iman Mirzadeh put it bluntly:
"Their process is not logical and intelligent."
The results suggest what looks like reasoning is often just pattern matching – statistically fluent but not grounded in logic.
Not all experts were dismissive. Sean Goedecke, a software engineer specializing in AI systems, saw the failure as revealing.
"The model immediately decides 'generating all those moves manually is impossible,' because it would require tracking over a thousand moves. So it spins around trying to find a shortcut and fails," he wrote in his analysis of the Apple study. "The key insight here is that past a certain complexity threshold, the model decides that there's too many steps to reason through and starts hunting for clever shortcuts. So past eight or nine disks, the skill being investigated silently changes from 'can the model reason through the Tower of Hanoi sequence?' to 'can the model come up with a generalized Tower of Hanoi solution that skips having to reason through the sequence?'"
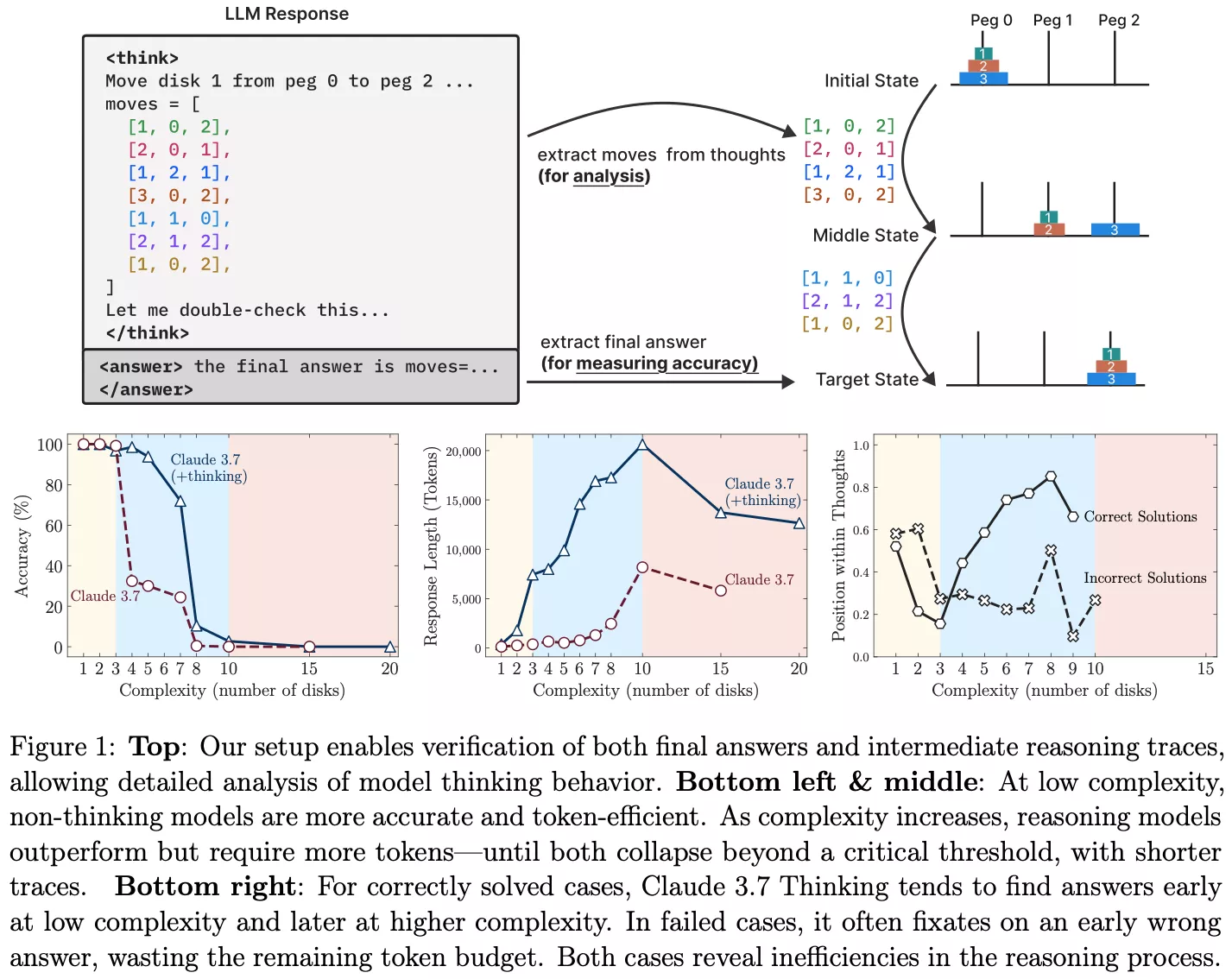
Rather than proving models are hopeless at reasoning, Goedecke suggested the findings highlight how AI systems adapt their behavior under pressure – sometimes cleverly, sometimes not. The failure isn't just in step-by-step reasoning but in abandoning the task when it becomes too unwieldy.
Tech companies often highlight simulated reasoning as a breakthrough. The Apple paper confirms that even models fine-tuned for chain-of-thought reasoning tend to hit a wall once cognitive load grows – for example, when tracking moves beyond six disks in Tower of Hanoi. The models' internal logic unravels, with some only managing partial success by mimicking rational explanations. Few display a consistent grasp of cause and effect or goal-directed behavior.
The results of the Apple and ETH Zurich studies stand in stark contrast to how companies market these models – as capable reasoners able to handle complex, multi-step tasks. In practice, what passes for reasoning is often just advanced autocomplete with extra steps. The illusion of intelligence arises from fluency and formatting, not true insight.
The Apple paper stops short of proposing sweeping fixes. However, it aligns with growing calls for hybrid approaches that combine large language models with symbolic logic, verifiers, or task-specific constraints. These methods may not make AI truly intelligent, but they could help prevent confidently wrong answers from being presented as facts.
Until such advances materialize, simulated reasoning is likely to remain what the name implies: simulated. It is useful – sometimes impressive – but far from genuine intelligence.
AI flunks logic test: Multiple studies reveal illusion of reasoning
