Why it matters: Currently available deep learning resources are falling behind the curve due to increasing complexity, diverging resource requirements, and limitations imposed by existing hardware architectures. Several Nvidia researchers recently published a technical article outlining the company's pursuit of multi-chip modules (MCM)s to meet these changing requirements. The article presents the team's stance on the benefits of a Composable-On-Package (COPA) GPU to better accommodate various types of deep learning workloads.

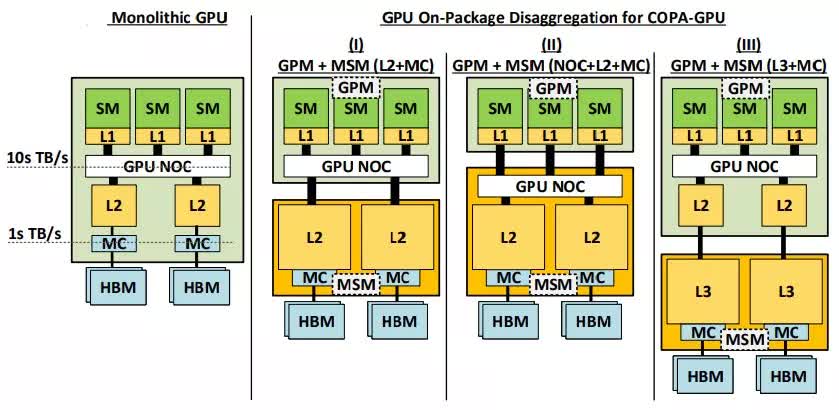
Graphics processing units (GPUs) have become one of the primary resources supporting DL due to their inherent capabilities and optimizations. The COPA-GPU is based on the realization that traditional converged GPU designs using domain-specific hardware are quickly becoming a less than practical solution. These converged GPU solutions rely on an architecture consisting of the traditional die as well as incorporation of specialized hardware such as high bandwidth memory (HBM), Tensor Cores (Nvidia)/Matrix Cores (AMD), ray tracing (RT) cores, etc. This converged design results in hardware that may be well suited for some tasks but inefficient when completing others.
Unlike current monolithic GPU designs, which combine all of the specific execution components and caching into one package, the COPA-GPU architecture provides the ability to mix and match multiple hardware blocks to better accommodate the dynamic workloads presented in today's high performance computing (HPC) and deep learning (DL) environments. This ability to incorporate more capability and accommodate multiple types of workloads can result in greater levels of GPU reuse and, more importantly, greater ability for data scientists to push the boundaries of what is possible using their existing resources.
Though often lumped together, the concepts of artificial intelligence (AI), machine learning (ML), and DL have distinct differences. DL, which is a subset of AI and ML, attempts to emulate the way our human brains handle information by using filters to predict and classify information. DL is the driving force behind many automated AI capabilities that can do anything from drive our cars to monitoring financial systems for fraudulent activity.
While AMD and others have touted chiplet and chip stack technology as the next step in their CPU and GPU evolution over the past several years—the concept of MCM is far from new. MCMs can be dated back as far as IBM's bubble memory MCMs and 3081 mainframes in the 1970s and 1980s.
