krizby
Posts: 429 +286
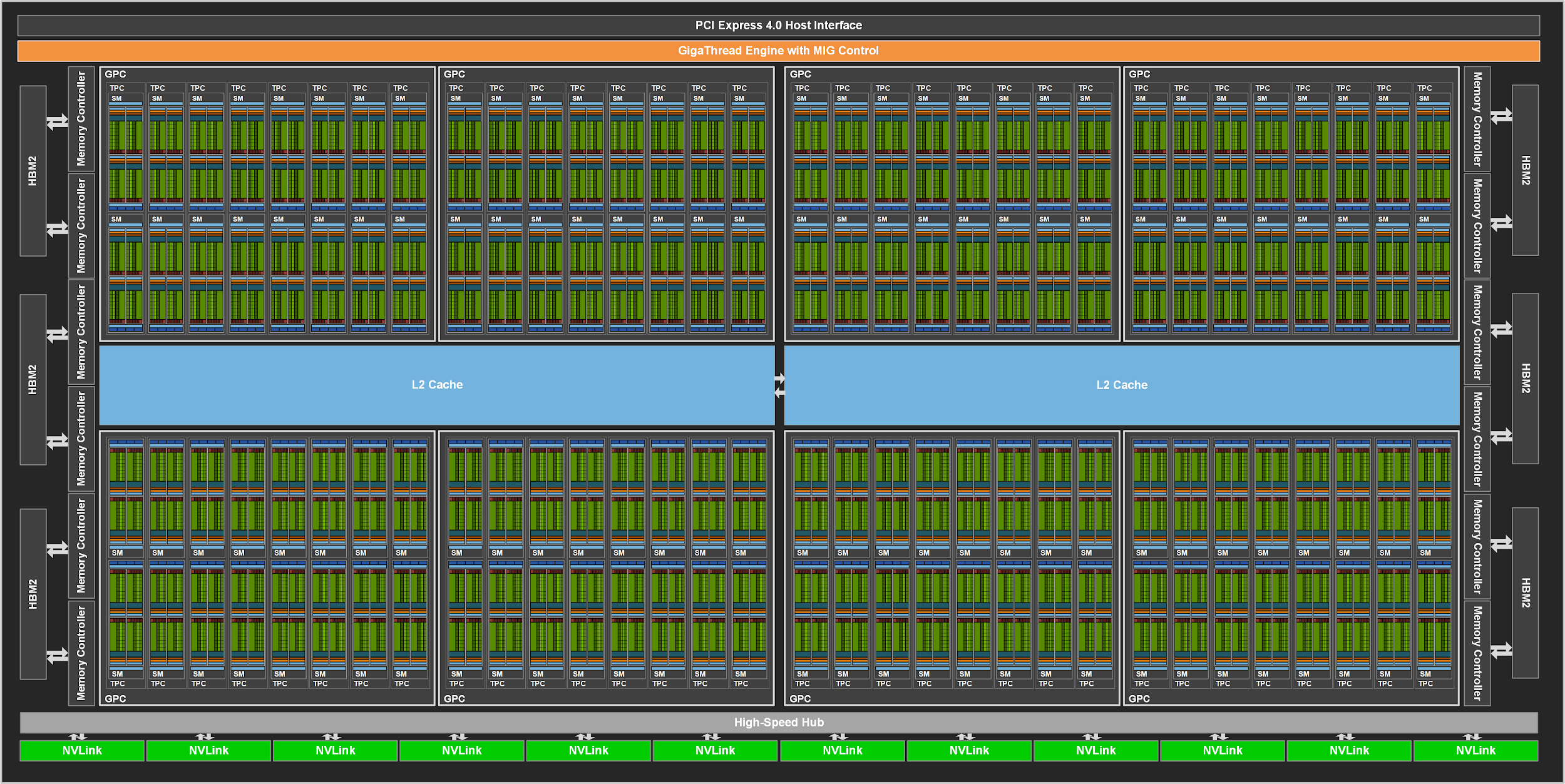
It's even more impressive when you realise that the stated die areas includes the HBM/HBM2.
The bulk of the changes lies within the tensor cores, of course, but the rest of the chip is essentially 'big-Volta', I.e. more SMs, more cache (a lot more L2, over 6 times more), more memory controllers, more NV Links:
Biggest question for me is how is this all going to get scaled down to keep the power consumption sensible: the A100's TDP is 400W, which is 150W more that the Tesla V100 SXM2 32GB. Obviously dropping the HBM2 will help quite a bit, as will hoofing off a few SMs, but it's still going to be high. 300W maybe?
Given that tensor cores only do matrix FMA, this is unlikely. The RT cores are specialised ASICs, two in fact: one for handling ray-triangle intersection calculations and the other for accelerating BVH algorithms. The tensor cores are used for denoising the images - but given that Ampere's are far more capable than Turing's, we're more likely to just see fewer TCs per SM, to allow for more RTCs. Or now that DLSS is TC-based, we could see this being pushed far more to offset the RT performance hit.
Now there is some confusion, I don't think the 826mm2 die size include the HBM2 at all, 826mm2 is the GPU die size alone.
Looking at the Vega Frontier Tear-down, the total size of the interposer + GPU is 30x30mm (900mm2), while the reported die size is ~495mm2 (20x26mm as measured by GamerxNexus). Each HBM stack is around 120mm2.
Nvidia can just use a lower voltage to improve efficiency on Ampere, as they had been doing with Turing.
Oh looking at A100 TC can do FP32 so I took that into the RTX-OPS calculations, but let say RT calculations are done on shader cores as with Pascal and Volta, the A100 already has higher RTX-OPS than 2080 Ti without any RTC (19.5 x 0.8) + (19.5 x 0.28) + (312 x 0.2) = 83.46 Tera RTX - OPS
Last edited:
 (Y)")