You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD Ryzen 5 9600X Review: Poor Value for Gamers
- Thread starter Steve
- Start date
Endymio
Posts: 5,032 +4,751
Read what I said. Intel first put SIMD support on their CPUs in 1999, before GPUs existed as such. They renamed it to AVX in 2008 and widened it to 256 bits, then 512. The fact remains that any software which can benefit from that level of SIMD parallelism can better benefit from it by using the GPU instead, which supports not only vector ops that are effectively millions of bits wide, but tensor ops as well.Or are you really saying Intel put AVX-512 on CPU and then just decided not to use it because, oh, well
Wrong. Main reason why Intel support AVX is latency. Offloading calculations for GPU takes ages latency wise. Therefore CPU is much faster on many cases.Read what I said. Intel first put SIMD support on their CPUs in 1999, before GPUs existed as such. They renamed it to AVX in 2008 and widened it to 256 bits, then 512. The fact remains that any software which can benefit from that level of SIMD parallelism can better benefit from it by using the GPU instead, which supports not only vector ops that are effectively millions of bits wide, but tensor ops as well.
But for your original point, you say Intel is ditching AVX512 because GPUs. Most Intel GPUs however are low end trash. Also what is AVX10 that Intel will support soon? While 512-bit wide vectors are optional there, Intel still maintain possibility to use is. So no, Intel is NOT ditching 512-bit AVX calculations. That also means Intel just had to disable them because panic solution didn't like two different cores.
Endymio
Posts: 5,032 +4,751
Glad you asked. AVX10 is a simplified version of AVX that drops mandatory 512-bit support:...Also what is AVX10 that Intel will support soon?
"The first and "early" version of AVX10, notated AVX10.1, will not introduce any instructions or encoding features beyond what is already in AVX-512...AVX10.2/256 indicates that a CPU is capable of the second version of AVX10 with a maximum vector width of 256 bits"
Going forward, 512 bit support will only be available on Intel server chips.
You miss the point. When the number of bits you have to process is small, offload latency is indeed a big factor -- but for small workloads, the difference between 256-bit and 512-bit SIMD is small. When you have billions (or trillions) of bits to process, though, offload latency becomes trivial compared to the cost of the operations themselves. I have a software package I run that supports either CPU (via AVX) or GPU modes. The GPU mode is some 5,000% percent faster than the CPU mode, despite the "higher latency".Wrong. Main reason why Intel support AVX is latency. Offloading calculations for GPU takes ages latency wise. Therefore CPU is much faster on many cases.
If chip real estate were free, then AVX-1024 or even AVX-8192 would make sense. But every transistor you use for AVX is one less you have in your budget elsewhere.
Last edited:

About whole point of AVX10 is that P-cores can support 512 bits and crap cores less. Right now when crap cores don't support 512 bits, P-cores cannot either. It's not "simplified" but rather offers optional vector length. Something that is missing on current AVX implementations.Glad you asked. AVX10 is a simplified version of AVX that drops mandatory 512-bit support:
"The first and "early" version of AVX10, notated AVX10.1, will not introduce any instructions or encoding features beyond what is already in AVX-512...AVX10.2/256 indicates that a CPU is capable of the second version of AVX10 with a maximum vector width of 256 bits"
Going forward, 512 bit support will only be available on Intel server chips.
For some reason, Zen5 is much faster on AVX512 workloads than Zen4 when using AVX512 supporting software. Not "small" difference. Also for some reason those calculations are not offloaded on GPU. Look at Phoronix 9700X review for more info. 512 bits is right now very possible on desktop too as we can see on Zen5. Transistor budget have not been issue for long time. Zen5 chiplet packs 8 cores under 71mm2. Leaving out L3 cache, cores are very tiny.You miss the point. When the number of bits you have to process is small, offload latency is indeed a big factor -- but for small workloads, the difference between 256-bit and 512-bit SIMD is small. When you have billions (or trillions) of bits to process, though, offload latency becomes trivial compared to the cost of the operations themselves. I have a software package I run that supports either CPU (via AVX) or GPU modes. The GPU mode is some 5,000% percent faster than the CPU mode, despite the "higher latency".
If chip real estate were free, then AVX-1024 or even AVX-8192 would make sense. But every transistor you use for AVX is one less you have in your budget elsewhere.
"Poor value for gamers..."
But incredible value for compute...
Zen 5 might be the most efficient leap in x86 CPUs history.
"Coming from our geomean averages, where we saw that the 9700X beat the 7700 by 25%, looking at our individual scores we can see that AMD has significantly improved their floating point performance across virtually the entire board. Not only does the 9700X cleanly beat the 7700 in every last test here, but no sub-test score improves by less than 10%. So based on these results, there's little reason not to expect virtually all floating point workloads to benefit similarly."
-Anandtech on Zen 5 IPC
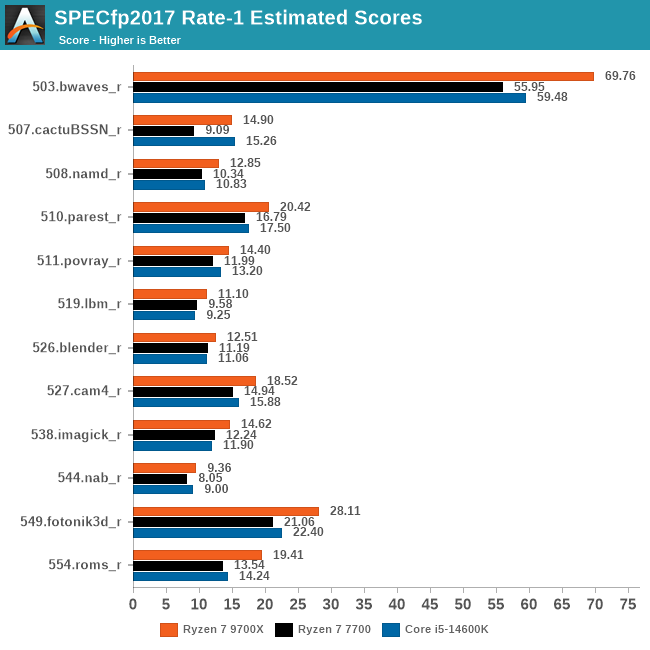
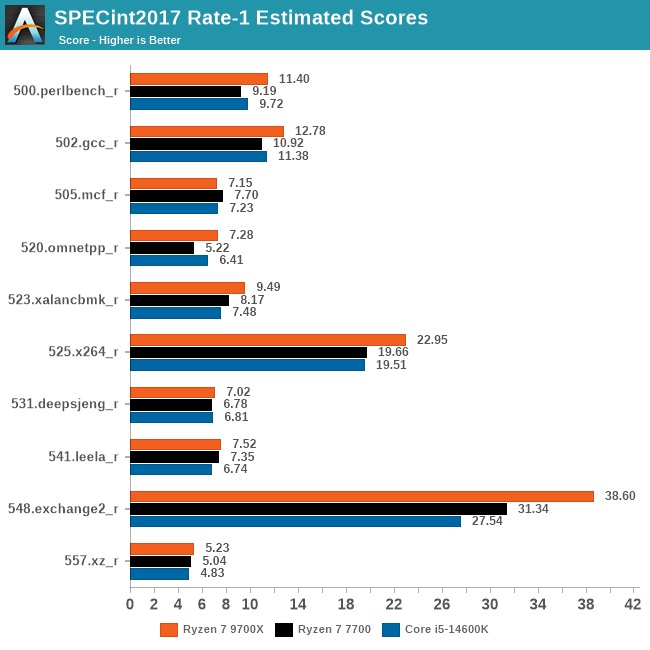
But incredible value for compute...
Zen 5 might be the most efficient leap in x86 CPUs history.
"Coming from our geomean averages, where we saw that the 9700X beat the 7700 by 25%, looking at our individual scores we can see that AMD has significantly improved their floating point performance across virtually the entire board. Not only does the 9700X cleanly beat the 7700 in every last test here, but no sub-test score improves by less than 10%. So based on these results, there's little reason not to expect virtually all floating point workloads to benefit similarly."
-Anandtech on Zen 5 IPC
Intel ditched AVX512 on desktop because their rendition was power hungry and barely anyone was using it.Bwahahaha. Intel only ditched AVX512 because their panic solution has two different type of cores and crappier one does not support AVX512. So to avoid too much compatibility problems, they had to disable it.
Or are you really saying Intel put AVX-512 on CPU and then just decided not to use it because, oh, well
On the other hand, AMD is implementing the same chiplets on desktop and datacenter for their business strategy. In reality, it is a great thing that client users can have access to the same compute performances as the datacenter users.
You are confusing Steve conclusion with reality.Here we go again...AMD hype train...overpromised and underdelivered.

IPC =/= Gaming IPC
Anandtech clearly demonstrated that the IPC gain is in the ballpark of AMD`s claims.
You can go back on WCCF now.
i like foxes
Posts: 312 +219
I5 14600K - 300 bucks
Ryzen 9600X - 280 bucks launch price/current
Ryzen 9600X in gaming on par // many different tests shows this
but Ryzen 9600X - 66W , I5 14600K- 76W . in regards to sys power draw - i5 14600k - 70-150W more
So , if Ryzen 9600X is bad , what is Intel i5 14600K ?
Just , AMD should lower the price
Ryzen 9600X - 280 bucks launch price/current
Ryzen 9600X in gaming on par // many different tests shows this
but Ryzen 9600X - 66W , I5 14600K- 76W . in regards to sys power draw - i5 14600k - 70-150W more
So , if Ryzen 9600X is bad , what is Intel i5 14600K ?
Just , AMD should lower the price
Intel ditched AVX512 on desktop because their rendition was power hungry and barely anyone was using it.
On the other hand, AMD is implementing the same chiplets on desktop and datacenter for their business strategy. In reality, it is a great thing that client users can have access to the same compute performances as the datacenter users.
Again, Alder/Raptor Lake P-cores do support AVX512. Early Alder Lake samples also supported it. Intel had to disable it however because panic solution was already a mess (two different architectures on same chip caused crashes on games) and Crap cores did not support AVX512, meaning there was also two cores with different instruction sets.
AMD basically ditched AVX512 on mobile chips. It was physical choice, not "let's put ot on CPU and then disable it" like you say Intel did.
Endymio
Posts: 5,032 +4,751
I literally laughed aloud at this statement. How soon history is forgotten. There were several new CPU releases in the 1980s and early 1990s that saw efficiency leaps of well over 100% -- on any and all workloads, not simply FP performance.incredible value for compute...
Zen 5 might be the most efficient leap in x86 CPUs history.
That's a ballpark larger than any Olympic stadium.Anandtech clearly demonstrated that the IPC gain is in the ballpark of AMD`s claims.
QUOTE="Mr Majestyk, post: 2091276, member: 345657"]
Amazing how this review is diametrically opposite that of Tom's Hardware in gaming. They also found it good in productivity too. I'd like to know how TH found the stock 9600X 12% faster than the 14600K and 21% faster with PBO and you've found basically the opposite. You even found PBO to be basically useless again the exact opposite of TH's.
[/QUOTE]
TH uses jedec 5200 for default settings for zen4, 5600 for zen5, 5600 for intel-k and 4800 for intel non-k.
For intel, default power settings are also set.
Most of the gaming performance gains you see with tonshardware pbo are not the result of pbo, they are just using xmp 6000 cl30.
Also, the advantage of zen5 over zen4 in th tests is about half if not more provided by 5600 vs 5200.
Also, some of the values are wrong - for example, the incredibly low value of intel in watchdogs, I get about 145 fps in the benchmark against 105 for th.
I find the toms hardware gaming test incredibly deceitful and not corresponding to reality.
Amazing how this review is diametrically opposite that of Tom's Hardware in gaming. They also found it good in productivity too. I'd like to know how TH found the stock 9600X 12% faster than the 14600K and 21% faster with PBO and you've found basically the opposite. You even found PBO to be basically useless again the exact opposite of TH's.
[/QUOTE]
TH uses jedec 5200 for default settings for zen4, 5600 for zen5, 5600 for intel-k and 4800 for intel non-k.
For intel, default power settings are also set.
Most of the gaming performance gains you see with tonshardware pbo are not the result of pbo, they are just using xmp 6000 cl30.
Also, the advantage of zen5 over zen4 in th tests is about half if not more provided by 5600 vs 5200.
Also, some of the values are wrong - for example, the incredibly low value of intel in watchdogs, I get about 145 fps in the benchmark against 105 for th.
I find the toms hardware gaming test incredibly deceitful and not corresponding to reality.
m3tavision
Posts: 1,733 +1,510
" We didn't bother including PBO data in this review. With it enabled, the data was about the same; sometimes we saw a 1-3% improvement, but overall, much the same. The PBO default setting is a complete non-event, just like the 9600X. "
lol^
PBO is not for single core testing, but for multicore workloads and gaming. And odd, that we do not know what memory timing they used or even type of memory.
Surpassing the 5800X3D using nearly half the energy is a thing.
lol^
PBO is not for single core testing, but for multicore workloads and gaming. And odd, that we do not know what memory timing they used or even type of memory.
Surpassing the 5800X3D using nearly half the energy is a thing.
Phoronix results match other reviewers when comparing the same tests, like Blender, code compilation, video encoding with the exception of SVT-AV1, as not every test is using the AVX512 optimizations, and some others. Their average is way different because they test a lot of software that benefits from the changes made on Zen5, the AVX512 improvement in particular pushes it way up.Phoronix has shown how much better these chips are when linux is run on them (so all you linux fans should head over there). Is this then a windows problem much like the high core threadrippers suffered originally?
Cracken
Posts: 51 +67
Zen 5 will go into the worlds most powerfull x86 chips money can buy, beating its main competitor by a wide margin, yeah sure "overpromises" hahHere we go again...AMD hype train...overpromised and underdelivered.
EPYC is where the game is at for AMD, just like Xeon is for intel.
WhiteLeaff
Posts: 1,050 +2,034
Read what I said. Intel first put SIMD support on their CPUs in 1999, before GPUs existed as such. They renamed it to AVX in 2008 and widened it to 256 bits, then 512. The fact remains that any software which can benefit from that level of SIMD parallelism can better benefit from it by using the GPU instead, which supports not only vector ops that are effectively millions of bits wide, but tensor ops as well.
Sorry but that's a lie, GPUs can't perform the same tasks as CPUs, let alone with the same latency. Before the GPU started processing one command, the CPU would have executed dozens.
Endymio
Posts: 5,032 +4,751
The statement is correct; you simply failed to understand it. Hint: look up the term "SIMD", vis a vis MIMD in particular. Any operation a CPU can perform via AVX can indeed be performed by a GPU.Sorry but that's a lie, GPUs can't perform the same tasks as CPUs... let alone with the same latency.
I've already explained above while your statement, though true, has led you to a false conclusion. The hint here is what the "MD" stands for in SIMD. When a CPU executes an command, it does so on one or two operands. Using AVX, that single command operates on 8, 16, or even 32 operands. But with a GPU, that single command can operate on tens of thousands of operands at once....let alone with the same latency. Before the GPU started processing one command, the CPU would have executed dozens.
WhiteLeaff
Posts: 1,050 +2,034
Nope, it's still inaccurate. You can't, for example, run a JIT recompiler (which uses AVX512) like the one implemented in RPCS3 on a GPU, certain software depends on granularity and ultra low latency.The statement is correct; you simply failed to understand it. Hint: look up the term "SIMD", vis a vis MIMD in particular. Any operation a CPU can perform via AVX can indeed be performed by a GPU.
I've already explained above while your statement, though true, has led you to a false conclusion. The hint here is what the "MD" stands for in SIMD. When a CPU executes an command, it does so on one or two operands. Using AVX, that single command operates on 8, 16, or even 32 operands. But with a GPU, that single command can operate on tens of thousands of operands at once.
Endymio
Posts: 5,032 +4,751
Oops! Flatly incorrect. Any instruction capable of being executed with AVX can be executed on a GPU instead. Period. Many JIT compilers do indeed have GPU support:Nope, it's still inaccurate. You can't, for example, run a JIT recompiler (which uses AVX512) on a GPU
IBM Java SDK: "You can enable the Just-In-Time (JIT) compiler to offload certain processing tasks to a general-purpose graphics processing unit (GPU). The JIT determines when to offload these tasks based on performance heuristics."
How the JIT compiler uses a GPU (Linux, Windows only)
You can enable the Just-In-Time (JIT) compiler to offload certain processing tasks to a general-purpose graphics processing unit (GPU). The JIT determines when to offload these tasks based on performance heuristics.
www.ibm.com
Or this for .NET:
"ILGPU is a JIT (just-in-time) compiler for high-performance GPU programs written in .Net-based languages. It offers the flexibility and the convenience of C++ AMP on the one hand and the high performance of Cuda programs on the other hand...."
How the JIT compiler uses a GPU (Linux, Windows only)
You can enable the Just-In-Time (JIT) compiler to offload certain processing tasks to a general-purpose graphics processing unit (GPU). The JIT determines when to offload these tasks based on performance heuristics.
www.ibm.com
The fact that one free, open-source package has chosen to not provide GPU acceleration does not mean it is "impossible".
Mr Majestyk
Posts: 2,519 +2,344
That is a disastrous result. Ryzen 1600 > 3600 > 5600 > 7600 were all significant, 20%-ish (give or take) improvements in gaming performance, all while staying in the same 65W TDP. The 9600X being marginally faster than the 7600 in gaming is a big disappointment.
Zen 5 will probably be great for efficiency-sensitive markets like mobile and server, but the desktop chips so far (9600X and 9700X) have little reason to exist.
Just run them 105W TDP as they are clearly being starved of power for multi-core use. This is AMD's fault not Steve's, but as usual he is the harshest critic of AMD and his headlines are by far the most negative. His results are the worst of all testers I've read too. The fact he says PBO doesn't a difference though shows there are problems with his cpu's.
WhiteLeaff
Posts: 1,050 +2,034
No, the nature pointed out in these texts is not that of a similar recompiler, a GPU could never RECOMPILE with the latency required for real-time emulation of a complex system. GPUs are good at many tasks, but this is not one of them. It's not that the PS3 team chose it, it's that it's the only way, there isn't a single console emulator that runs JIT recompilers on the GPU. It's kind of crazy to suggest that.Oops! Flatly incorrect. Any instruction capable of being executed with AVX can be executed on a GPU instead. Period. Many JIT compilers do indeed have GPU support:
IBM Java SDK: "You can enable the Just-In-Time (JIT) compiler to offload certain processing tasks to a general-purpose graphics processing unit (GPU). The JIT determines when to offload these tasks based on performance heuristics."
How the JIT compiler uses a GPU (Linux, Windows only)
You can enable the Just-In-Time (JIT) compiler to offload certain processing tasks to a general-purpose graphics processing unit (GPU). The JIT determines when to offload these tasks based on performance heuristics.www.ibm.com
Or this for .NET:
"ILGPU is a JIT (just-in-time) compiler for high-performance GPU programs written in .Net-based languages. It offers the flexibility and the convenience of C++ AMP on the one hand and the high performance of Cuda programs on the other hand...."
How the JIT compiler uses a GPU (Linux, Windows only)
You can enable the Just-In-Time (JIT) compiler to offload certain processing tasks to a general-purpose graphics processing unit (GPU). The JIT determines when to offload these tasks based on performance heuristics.www.ibm.com
The fact that one free, open-source package has chosen to not provide GPU acceleration does not mean it is "impossible".
Nintenboy01
Posts: 358 +268
Yeah sounds like Steve had issues with his chip or maybe BIOS settings or a weird motherboard or something. Funny to see it only slightly ahead of a 5800X3D in many games.
Personally I think if you're on a mostly gaming-focused build using a 5800X3D you might as well wait until AM6/DDR6 to upgrade. Or see if ARM starts taking over from x86 little by little.
Personally I think if you're on a mostly gaming-focused build using a 5800X3D you might as well wait until AM6/DDR6 to upgrade. Or see if ARM starts taking over from x86 little by little.
Yeah sounds like Steve had issues with his chip or maybe BIOS settings or a weird motherboard or something. Funny to see it only slightly ahead of a 5800X3D in many games.
Personally I think if you're on a mostly gaming-focused build using a 5800X3D you might as well wait until AM6/DDR6 to upgrade. Or see if ARM starts taking over from x86 little by little.
I dont think Steves review is off or anything wrong, remember, all these reviews are going to be a little off, memory timings, etc vary on all these reviews, and unlike Intel, they make a difference on AMD cpus.
Toms 21% increase was with a OC on the memory to 6000 when here he was using 5600.
Similar threads
- Replies
- 23
- Views
- 552
- Replies
- 10
- Views
- 235
Latest posts
-
 Testing AMD Radeon's Biggest-Ever Software Upgrade: FSR 4.1 on RDNA 3
Testing AMD Radeon's Biggest-Ever Software Upgrade: FSR 4.1 on RDNA 3- CapNemo72 replied
-
 The latest from our Trillionaire "Genius"
The latest from our Trillionaire "Genius"- wiyosaya replied
-
Sony will stop making physical PlayStation games starting in 2028
- Revolution 11 replied
-
TechSpot is dedicated to computer enthusiasts and power users.
Ask a question and give support.
Join the community here, it only takes a minute.