In context: Google Translate may have started as a fairly rudimentary translation tool that you only used when absolutely necessary, but it's come a long way since those early days. Now, courtesy of Google Translate's built-in AI features, the tool is invaluable for translating everything from a few sentences to entire web pages; usually with a high degree of accuracy and readability.
A new post published on Google's AI Blog shows that the search giant isn't interested in leaving well-enough alone. Instead of focusing on traditional speech-to-text, text-to-text, or text-to-speech translation, the company is jumping leaping into the future with a speech-to-speech translation system that can preserve a speaker's unique voice characteristics, such as tone, inflection, and cadence.
Google is accomplishing this feat through "Translatotron," a tool that utilizes a "sequence-to-sequence network" to convert source spectrograms (a visual representation of frequencies, as Engadget explains) into translated spectrograms in a given target language.
To preserve a speaker's tone as mentioned before, Google relies on an optional "speaker encoder" step that can "maintain the character of the source speaker’s voice in the synthesized translated speech."
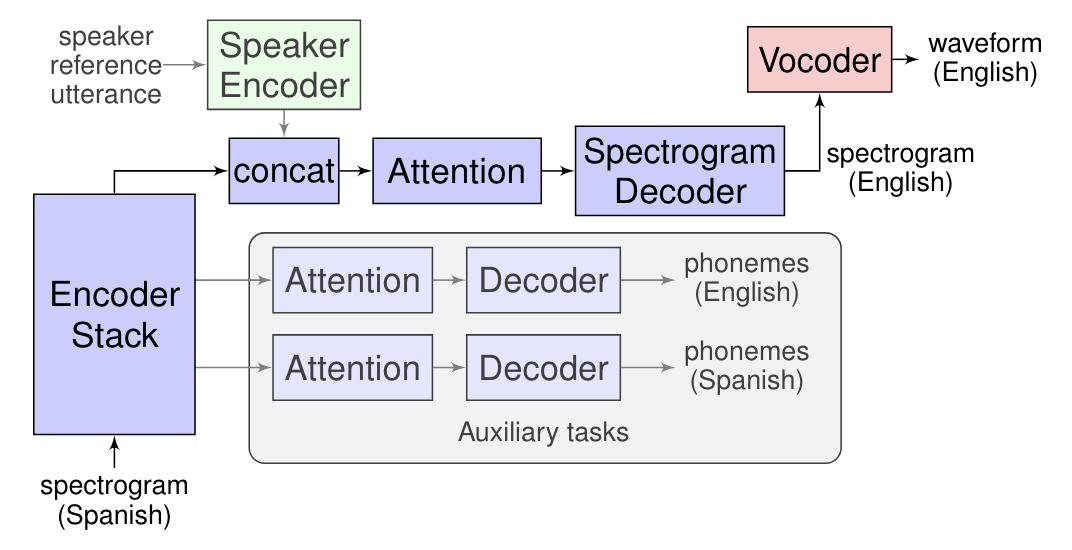
The full explanation of how Translatotron works is fairly technical in nature, but from a practical perspective, you should be able to say something like "My name is John, how are you?" in English to someone who only speaks Spanish and have the tool convey your message more quickly and accurately than ever before.
You can read all of the details behind Translatotron's functionality and listen to a few before-and-after voice samples right here. Unfortunately, as interesting as the tool sounds, Translatotron does not appear to be available for the general public just yet, and there's no word on when it might launch -- perhaps it will quietly be added to Google Translate itself in the future.

