Ripple effect: An Amazon Web Services outage knocked dozens of popular online platforms offline across much of the world, including Amazon, Alexa, Ring, Snapchat, Reddit, Fortnite, ChatGPT, and the Epic Games Store. The disruption lasted for hours, with AWS restoring service after a series of "cascading" failures.

Amazon notes that last week's AWS outage began at 11:48 PM PDT on October 19, as users reported widespread errors and latency across services in the US-EAST-1 region (Northern Virginia). Amazon confirmed the disruption stemmed from DNS resolution problems with the DynamoDB API endpoint. While engineers mitigated the issue within about 11 hours, full recovery across all impacted services took roughly 16 hours, affecting users across multiple time zones throughout the day.
Ars Technica notes that the outage originated from a software bug in a DNS management component used by DynamoDB, one of AWS's core database services. A race condition – essentially a timing glitch between two overlapping processes – caused an older DNS plan to overwrite a newer one, erasing all IP addresses for a key regional endpoint.

That single misfire crippled DynamoDB and rippled outward, taking down services that relied on it for authentication, data access, or internal routing. Dependent services such as Lambda, Fargate, and Redshift were unable to create or modify new instances until network state propagation caught up, extending the impact well into the following day.
Ookla's Downdetector data offers a sense of the scale. The platform logged more than 17 million user reports from 60 countries, with the United States alone accounting for over six million. Snapchat, Roblox, Reddit, and Amazon's own retail and Ring services topped the list of affected platforms. Even national government sites, financial institutions, and education tools experienced outages tied to the same regional fault.
The affected US-EAST-1 region – Amazon's oldest and most heavily used hub – has long been considered the backbone of the AWS cloud infrastructure. As Ookla pointed out, even "global" applications often anchor key functions like identity, state, or metadata flows there. When that single region falters, the effect cascades worldwide. Since so many apps chain multiple AWS services together, the DNS failure spread far beyond Amazon's control, affecting users who had no idea their favorite platforms even touched the service.
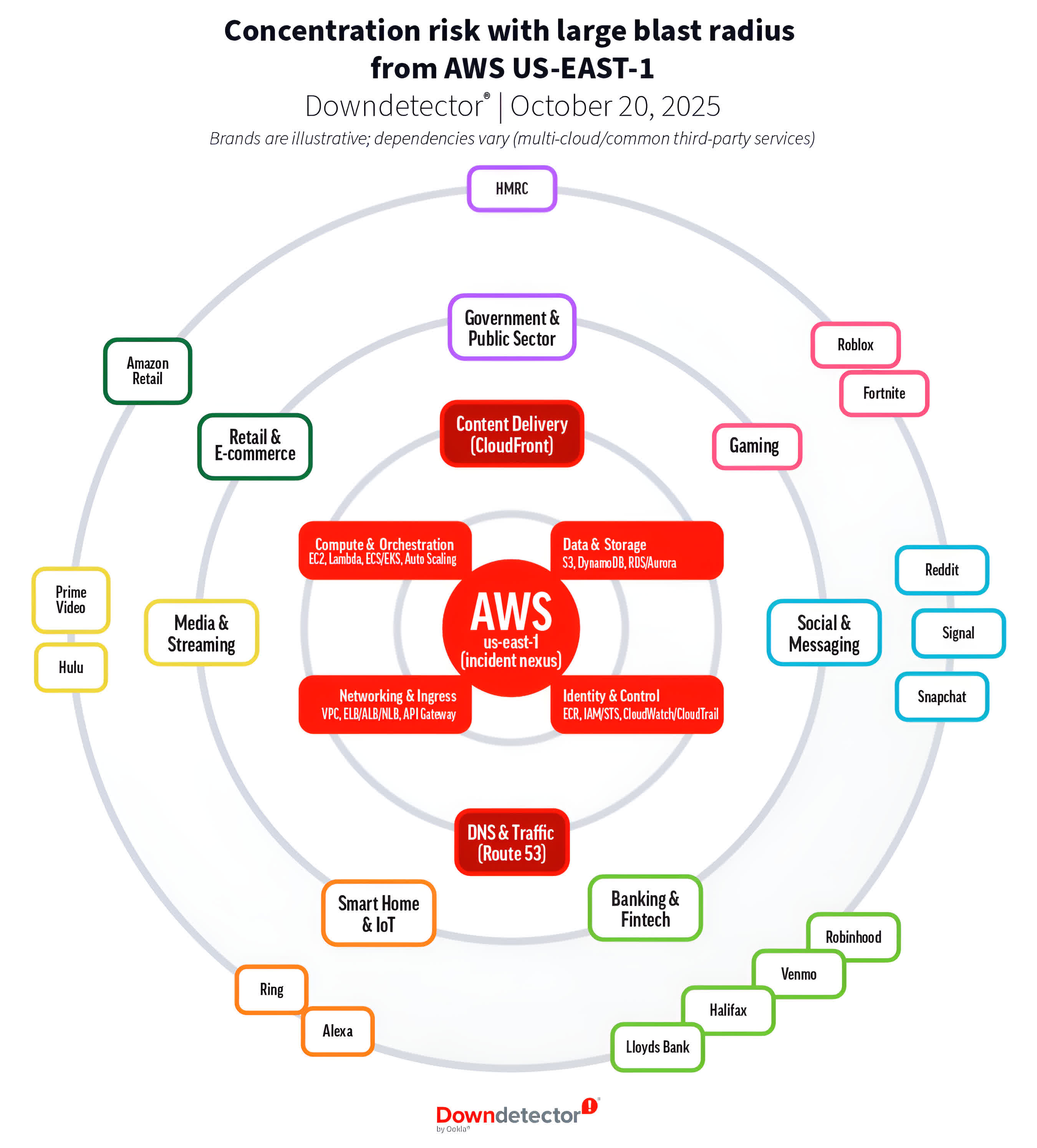
Amazon has since disabled DynamoDB DNS automation globally and is redesigning the problematic system to prevent similar race conditions. Still, the episode exposed an uncomfortable truth: redundancy at the physical layer means little when logical dependencies remain concentrated in a single region. The outage showed that a minor software flaw – buried deep within a complex web of automation – can ripple through the global internet in minutes.
The incident was not entirely preventable. However, experts recommend providers implement multi-region designs, dependency diversity, and realistic disaster drills that simulate regional loss to help contain cascading events. They advise cloud customers to practice "graceful slowdowns" to keep essential features online to preserve user trust during partial outages.
More broadly, the event shows how cloud providers have become systemic infrastructure, critical not just to commerce but to communication and governance. As policymakers in the EU and UK move to regulate key cloud providers as the AWS incident will likely reinforce calls for stronger oversight and transparency in how digital backbones are built and maintained.
Amazon reveals a single point of failure brought down AWS taking thousands of services with it