The takeaway: AMD is exploring a new approach to system memory that could reshape the trajectory of DDR5, which has struggled to keep pace with the performance demands of gaming, artificial intelligence, and data-intensive computing. A recently published patent, first reported by Tech4Gamers, outlines what the company calls a "high-bandwidth memory module architecture" – a design intended to extend the usefulness of DDR5 technology without requiring fundamental changes to its underlying chips.

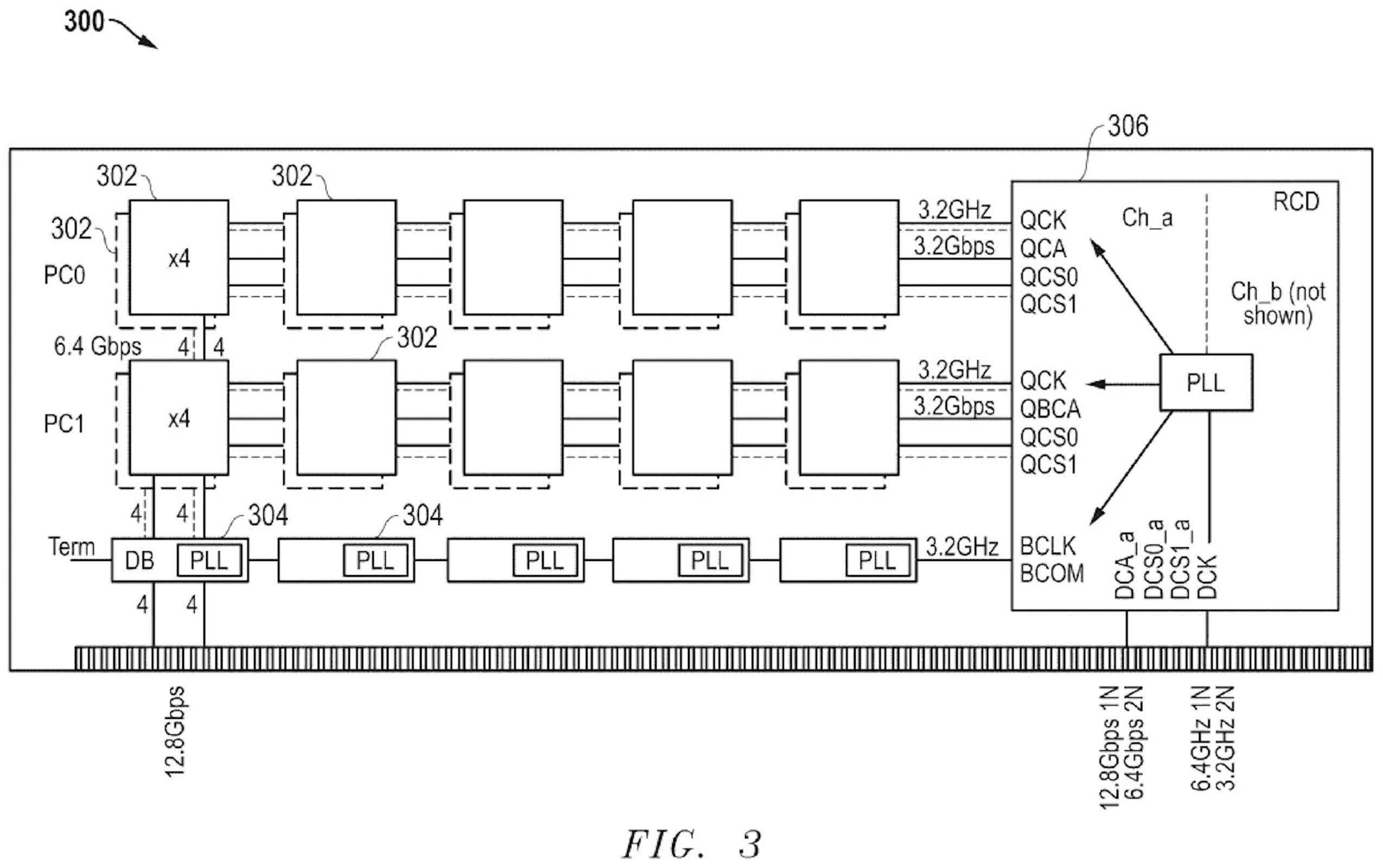
The patent describes the development of high-bandwidth dual inline memory modules (HB-DIMMs) that use pseudo channels and specialized data routing to boost performance. Rather than re-engineering DRAM chips, AMD proposes coupling multiple DRAM devices to advanced data buffer chips. These buffers manage signal flow in a way that effectively doubles output, raising transfer speeds from the current 6.4 gigabits per second to 12.8 gigabits per second on the memory bus.
By working within the framework of established DRAM architectures, the design positions itself as an upgrade that could be adopted without industry-wide overhauls to manufacturing or platform standards. AMD argues that DDR5 in its current form is hitting performance ceilings just as system workloads are rapidly expanding.
An illustration of the formation of a high-bandwidth DIMM (HB-DIMM).
At the core of the architecture is a register clock driver circuit that decodes memory commands and routes them using a chip identifier bit. This approach allows the module to assign tasks to independently addressable pseudo channels, enabling true parallel access rather than the sequential limitations that typically constrain throughput.
The system also supports both 1n and 2n operating modes, providing flexibility in how clocks and signals are managed. This adaptability helps optimize timing margins, ensures compliance with DDR5 requirements, and reduces signaling complexity. Rather than relying on interleaved configurations, AMD's proposal adopts a simplified non-interleaved transfer format that lowers latency and improves signal integrity.
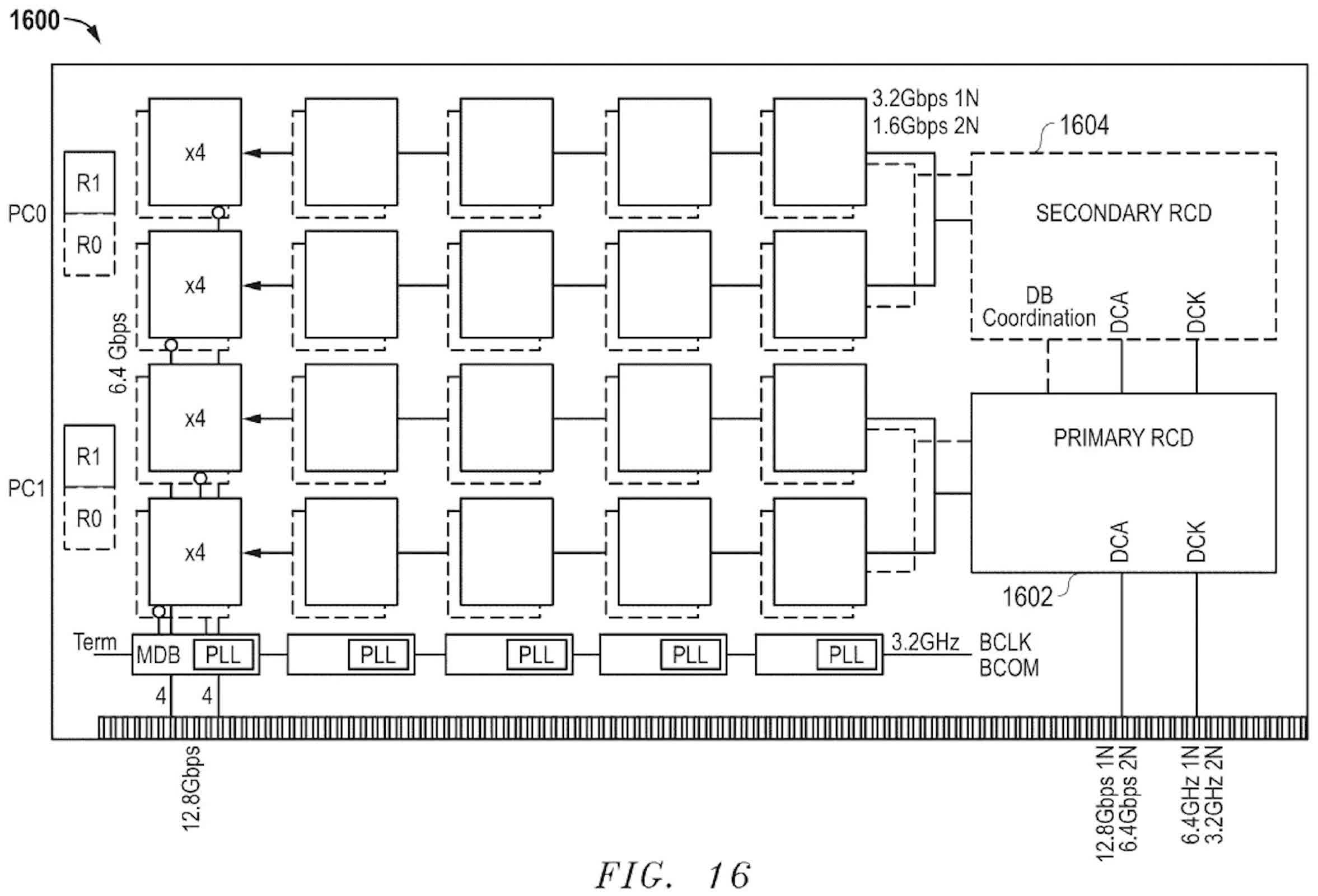
This is the HB-DIMM memory architecture.
Another feature of the design is its ability to switch between pseudo-channel operation and quad-rank configurations. This versatility makes it well-suited for high-performance computing scenarios, where striking a balance between throughput and flexibility is often critical. The broader goal is to reduce reliance on entirely new chip designs for memory scaling, instead focusing on extending the capabilities of existing DRAM technologies.
Tech4Gamers notes that this isn't the first time AMD has sought to address performance bottlenecks through incremental but impactful engineering advances. Recent patent filings include a blower fan design aimed at improving thermal management in gaming laptops and a cache-memory cleaning system intended to boost processor efficiency.
