Ripple effect: When Cloudflare experienced a massive outage on Monday, many people, including the company's engineers, initially suspected a sophisticated DDoS attack. The company later explained that a flawed update to its server infrastructure caused a single file to malfunction. Several major outages in recent years have resulted from similar single points of failure.

Cloudflare CEO Matthew Prince has published a detailed apology and explanation of the incident, which disrupted many popular online platforms. Uber, ChatGPT, McDonald's, League of Legends, X, the New Jersey Transit system, and even TechSpot experienced service interruptions for hours.
Because Cloudflare protects these and other sites from DDoS attacks and other threats, the company first assumed it was facing a major security incident when servers began failing at around 6:20 ET on Monday morning. Another reason for the initial assumption was that the outages appeared and disappeared over about two hours before becoming continuous around 8:00.
However, the company eventually discovered that, when it changed a permission in a database system under a mistaken assumption about its behavior, it doubled the size of a file critical to Cloudflare's bot manager. This manager, which directs automated traffic through the company's systems, updates continuously in response to ever-evolving threats but also contains certain file size limits to minimize memory consumption and ensure smooth performance.
When the bot manager updated with the inflated file, which exceeded those limits, the result was an error. The glitches were initially intermittent due to the time needed for the faulty file to update throughout the entire system. Cloudflare resolved the issue by reverting to an earlier version of the file at 11:30 and had restored all operations by noon.
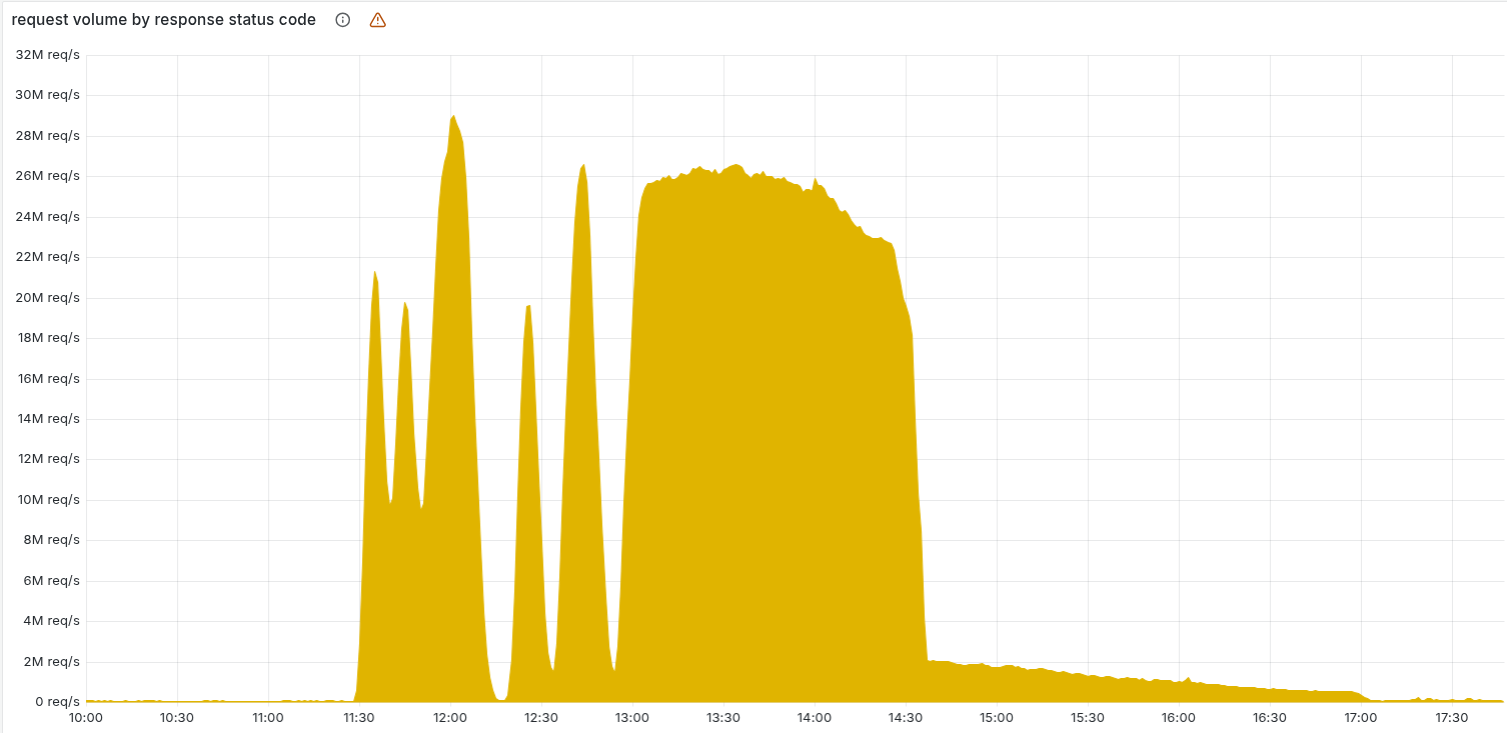
This chart shows the volume of 5xx errors served by the Cloudflare network. Normally this should be very low, but the peaks show when the outage first manifested and then fully unchained.
Prince described the incident as the company's worst since a major outage in 2019 and promised that Cloudflare would review the affected systems and return stronger. However, the event is only the latest example of a small mistake causing a major outage.
In October, a glitch in a single database server caused a major Amazon Web Services outage that took ChatGPT, Fortnite, Reddit, Amazon, and other popular services offline. One of the most serious incidents of this kind occurred last July, when a faulty CrowdStrike security update triggered the infamous Blue Screen of Death on critical Windows systems worldwide. The outage affected broadcasters, transportation services, and numerous other businesses.
And so this is how a tiny Cloudflare update broke huge chunks of the internet
")

