Why it matters: An interesting article posted at WikiChip discusses the severity of SRAM shrinkage problems in the semiconductor industry. Manufacturer TSMC is reporting that its SRAM transistor scaling has completely flatlined to the point where SRAM caches are staying the same size on multiple nodes, despite logic transistor densities continuing to shrink. This is not ideal, and it will force processor SRAM caches to take up more space on a microchip die. This in turn could increase manufacturing costs of the chips and prevent certain microchip architectures from becoming as small as they could potentially be.

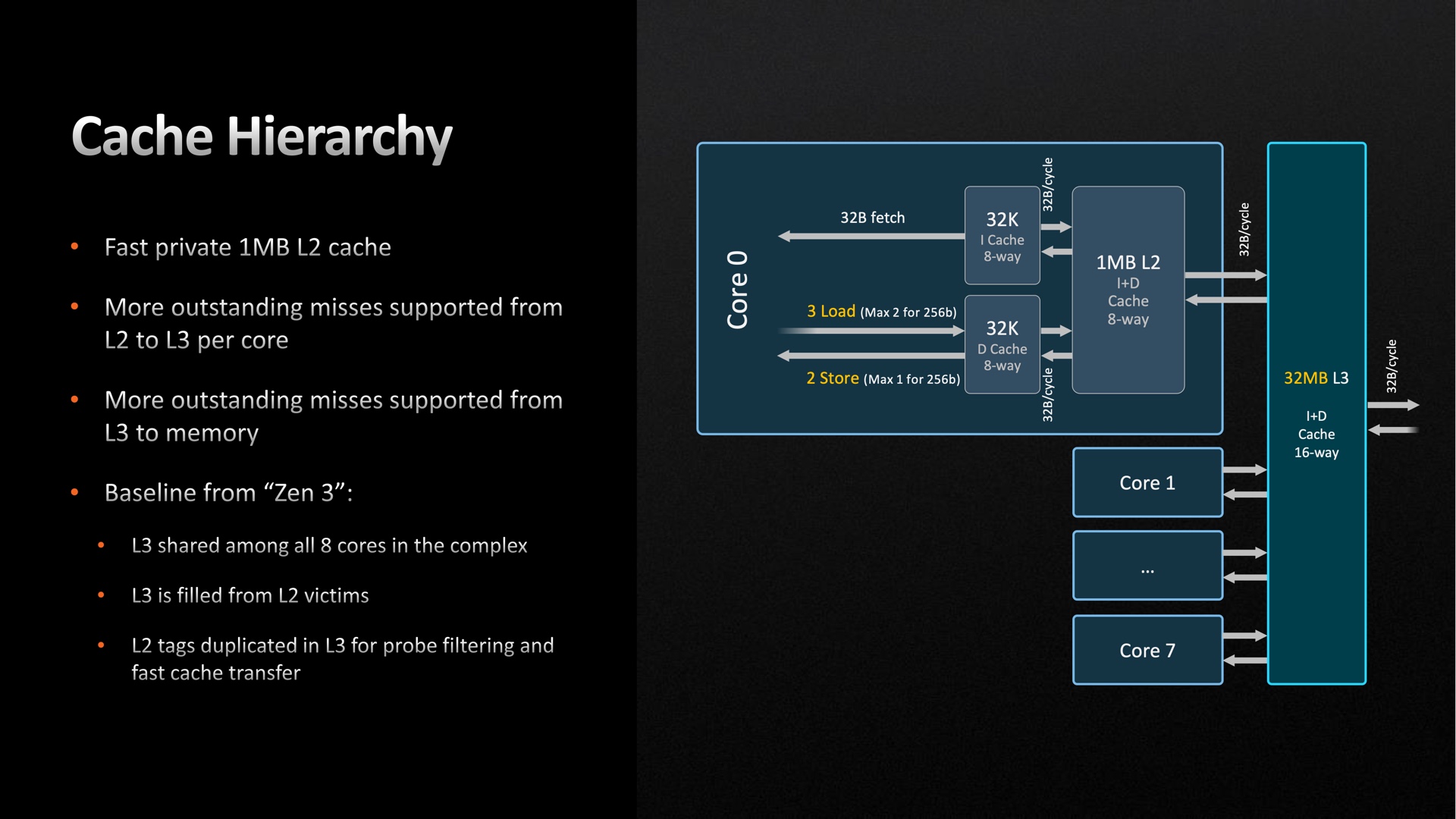
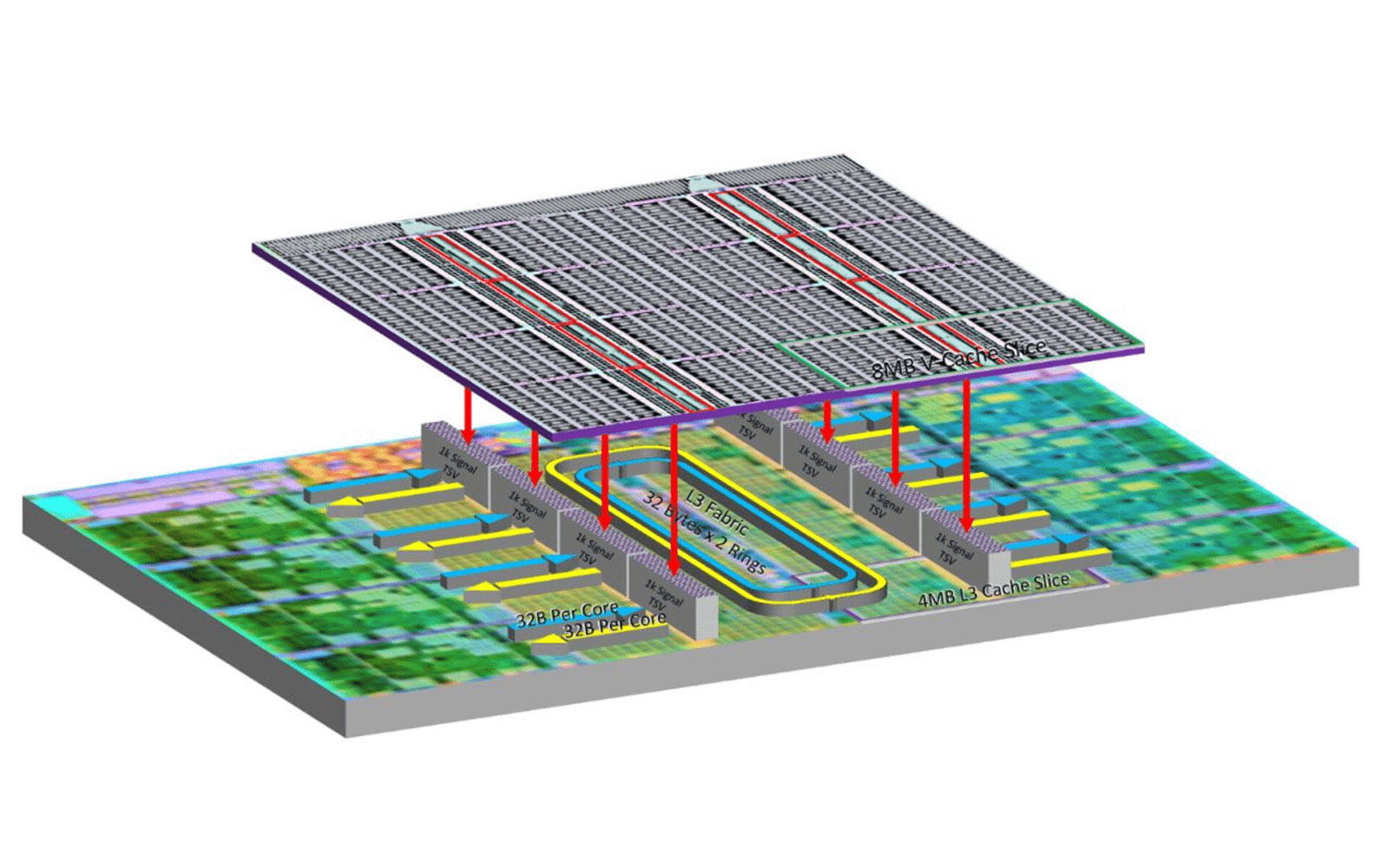
Nearly all processors rely on some form of SRAM caching. Caches act as a high speed storage solution with very fast access times due to their strategic placement right next to the processing cores. Having fast and accessible storage can significantly increase processing performance and result in less wasted time for the cores to do their work.
At the 68th Annual IEEE International EDM conference, TSMC revealed huge problems with SRAM scaling. The company's next node it is developing for 2023, N3B, will include the same SRAM transistor density as its predecessor N5, which is used in CPUs like AMD's Ryzen 7000 series.
Another node currently in development for 2024, N3E is not that much better, featuring a measly 5% reduction in SRAM transistor size...
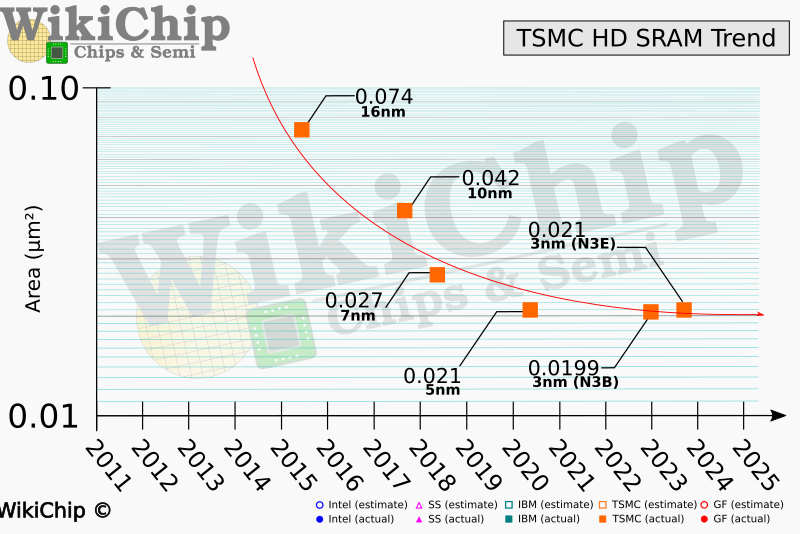
For a broader perspective, WikiChip shared a graph of TSMC's SRAM scaling history from 2011 to 2025. The first half of the graph -- representing TSMC's 16nm and 7nm days -- shows how SRAM scaling was not a issue and how it was getting smaller at a rapid pace. But once the graph hits 2020, scaling basically flatlines, with three generations of TSMC logic nodes using nearly identical SRAM sizes: N5, N3B and N3E.
With logic transistor density still increasing at a rapid pace -- up to 1.7x in the case of N3E -- but without SRAM transistor density following the same path, SRAM will start consuming a lot of die space as time goes on. Wikichip demonstrated this with a hypothetical 10 billion transistor chip, operating on several nodes. On N16 (16nm), the die is large with just 17.6% of the die area composed of SRAM transistors, on N5, this goes up to 22.5%, and 28.6% on N3.
WikiChip also reports that TSMC isn't the only manufacturer with similar problems. Intel has also seen noticeable slowdowns in SRAM transistor shrinkage on its Intel 4 process.
Unless this is somehow remedied, we could soon see SRAM caches consuming as much as 40% of a processor's die space. This would lead to chip architectures having to be reworked and add to development costs. Another way manufacturers might cope is to lower cache capacity altogether, which would reduce performance. However, there are alternative memory replacements being looked at, including MRAM, FeRAM, and NRAM, to name a few. But for now, it remains a challenge with no clear answer in the immediate future.
https://www.techspot.com/news/97000-cpu-gpu-sram-caches-not-shrinking-which-could.html