WTF?! Many people have probably heard of FPGA from its applications for legacy hardware emulation. A recent FPGA demonstration, however, managed to run a simple game utilizing ray tracing – something typically associated with the most advanced graphics processors.
A pair of new workflow tools from two developers has allowed a modest FPGA chip to achieve stunning efficiency gains over a conventional x86 processor. The results could open new paths for energy-efficient operations across several industries.
The demonstration involved a game depicting little more than a shiny ball bouncing across a checkerboard surface. However, the game utilized real-time ray tracing, something no one would expect a medium-sized FPGA chip to handle. Furthermore, the FPGA processor ran the game using far less energy than a much more powerful AMD laptop CPU.
Developers Victor Suarez Rovere and Julian Kemmerer built the demo for an Artix 7 100T in C, expressing the code directly to the circuit using their tools – CflexHDL and PipelineC. Then, they compiled the same demo for a Ryzen 9 4900H, running entirely on the CPU without using its integrated graphics. Both chips ran the game at around 60 frames per second in 1080p but needed drastically different performance profiles for the task.
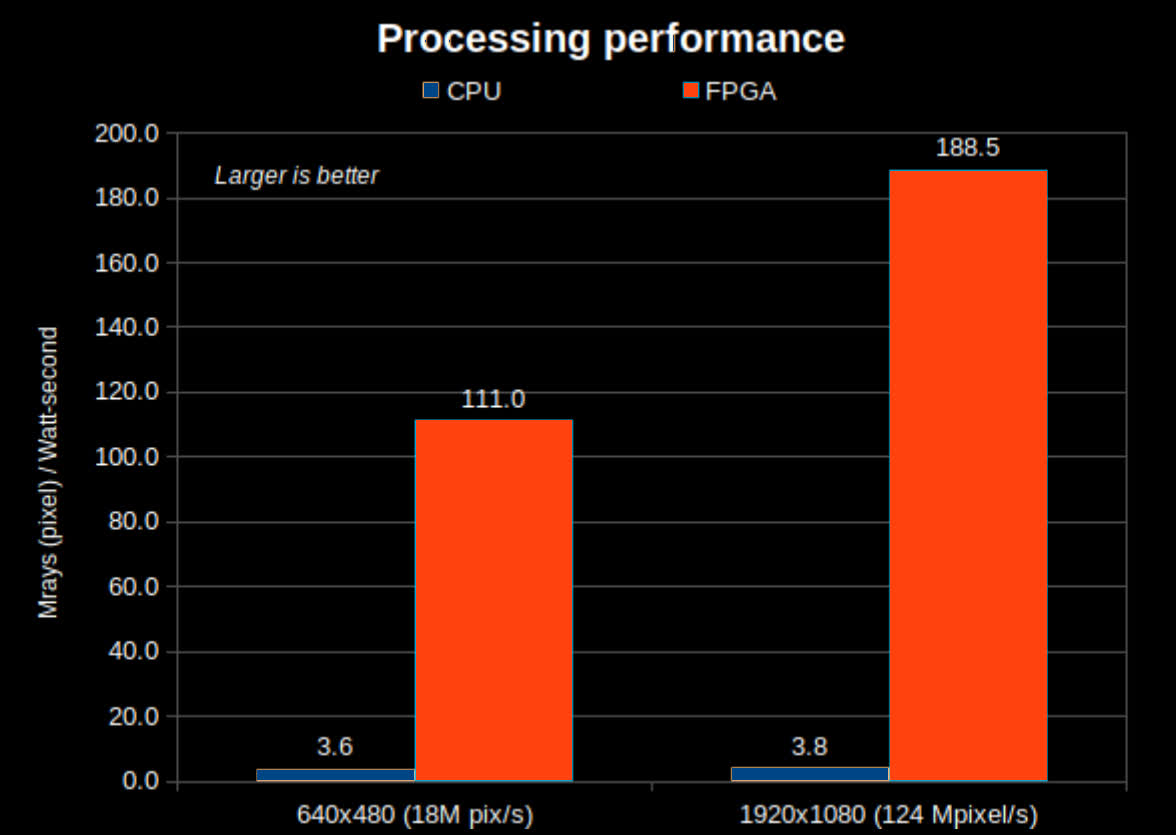
The Artix – based on a 28nm node process – ran at 148MHz with about 100,000 logic elements. The Ryzen, in comparison, is an 8-core 16-thread 7nm CPU. The developers ran all those threads near the processor's 4.2GHz maximum boost clock. Rovere and Kemmerer estimate that the Artix has about one-fifteenth the number of transistors as the Ryzen.
Despite the deficit, the FPGA part ran the demo using only 660mW and "stayed barely warm" despite a total lack of active cooling. The x86 chip, however, consumed 33W – 50 times more energy – and reached 88C with its fans at maximum to achieve the same performance.
Rovere and Kemmerer estimate that a 7nm FPGA chip would have multiplied the efficiency gap by a factor of six, needing 300 times less wattage than the Ryzen. To be fair, running the Ryzen in its intended environment with integrated graphics or a dedicated GPU would likely have been more efficient, but wouldn't have cleared the gap with the Artix, much less a more advanced FPGA part.
The developers think their demonstration could have applications far beyond game development. The tiny TDP requirements of methods like CflexHDL and PipelineC could have benefits in areas including aerospace, industrial control, or networking. Virtual Reality and Augmented Reality headsets could become smaller with longer battery life and less latency. For security, the fixed latency and lack of stored instructions could dramatically shrink a system's attack surface.
In the future, Rovere and Kemmerer plan to transfer their work to RISC-V and ASIC while making it open-source. Along with the above video, a white paper on GitHub explains the demonstration in-depth.
https://www.techspot.com/news/96141-fpga-chip-shown-over-50-times-more-efficient.html

")