Bottom line: China's DeepSeek has released detailed cost figures for training its R1 artificial intelligence model, providing rare insight into its development and drawing renewed scrutiny of the company's methods and resources. The Hangzhou-based startup said the model was trained for $294,000 using 512 Nvidia H800 chips, a cost far below estimates for US competitors and one that may intensify questions about how Beijing-backed firms are advancing in the global AI race.
The disclosure appeared in a peer-reviewed Nature paper this week, co-authored by founder Liang Wenfeng. The publication marks a rare move for DeepSeek, which has revealed little since its surprise debut on the international stage earlier this year. In January, the company's launch of lower-cost AI systems rattled markets, sending shares of major technology firms down as investors worried the competitive landscape could shift.
The reported $294,000 training cost stands in sharp contrast to estimates for US companies. OpenAI Chief Executive Sam Altman said in 2023 that training its foundation models cost "much more" than $100 million, though no detailed figures were provided.
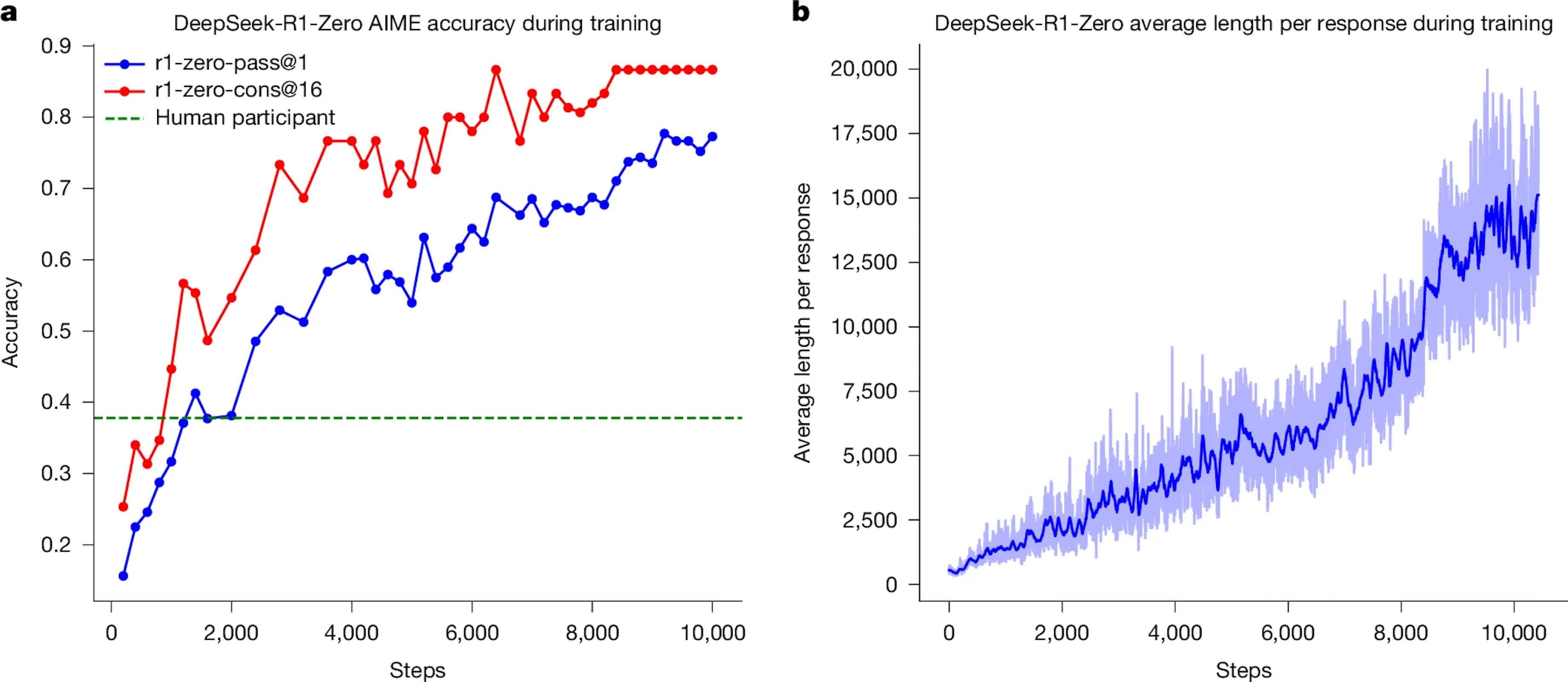
DeepSeek researchers said the R1 model was trained over 80 hours on a 512-chip cluster of Nvidia H800s, hardware the US chipmaker designed specifically for China's restricted market. A supplementary filing also acknowledged for the first time that DeepSeek owns Nvidia A100 units, which were used in early experiments with smaller models before the team shifted to H800 hardware.
Although the figures outlined in Nature suggest unusually low expenditures for training a frontier model, industry experts have raised doubts. Research firm SemiAnalysis reported that DeepSeek operated at a far larger scale than initially indicated, with access to roughly 50,000 Nvidia Hopper GPUs, including 10,000 H800s and 10,000 H100s. The firm argued that the widely cited $5.5 million pre-training figure represented only a narrow portion of the company's true costs.

According to SemiAnalysis, DeepSeek invested about $1.6 billion in servers, incurred roughly $944 million in operating costs, and spent more than $500 million specifically on GPUs. The findings challenge the perception that DeepSeek built frontier AI systems at only a fraction of US costs.
Beyond financials, the company also addressed longstanding questions about the origins of its models. Critics, including US officials and AI executives, have alleged that DeepSeek's progress relied heavily on distillation – a method in which a new model is trained on the outputs of another, allowing it to replicate knowledge at lower cost.
DeepSeek has consistently defended the practice, saying it enables more efficient systems that can be deployed affordably at scale. The company previously acknowledged incorporating Meta's open-source Llama in some distilled models.
In its Nature paper, DeepSeek researchers further admitted that training data for its V3 model included "a significant number" of responses generated by OpenAI systems. They described this as incidental, the result of crawled web data, rather than a deliberate attempt to replicate outside models.
Taken together, the cost disclosures, disputed claims, and methodological debates highlight the difficulty of verifying DeepSeek's true capabilities. Since its debut in January, the company has rolled out incremental product updates while keeping a relatively low public profile. Still, evidence of cost efficiency and alternative development methods could increase pressure on US firms grappling with soaring training expenses.
In rare disclosure, DeepSeek claims R1 model training cost just $294K
