In brief: Going fully offline for speech recognition opens up new possibilities as to how different AI elements can be included within Android OS and other mobile devices. Google's speech-to-text feature in Gboard is now fully capable of real time speech recognition while offline.
Digital assistants and voice-controlled gadgets have come a long way in just a few years. While eyes have been heavily focused on Amazon Alexa and Google Assistant as the leading voice recognition services, the technology behind them is hidden on remote servers. With the latest update to Gboard, Google's onscreen Android keyboard, speech recognition goes completely offline.
Traditional speech recognition algorithms take words and break them down into parts called phonemes. Each part would typically be a 10 millisecond segment which would then be processed. Latency of this method is not horrible, but there is a guarantee that the results will not be output in real time.
Google's new speech recognition software has been in the works since 2014. Instead of looking for pieces of each word, individual letters are recognized and output as soon as a complex set of neural networks do their magic.
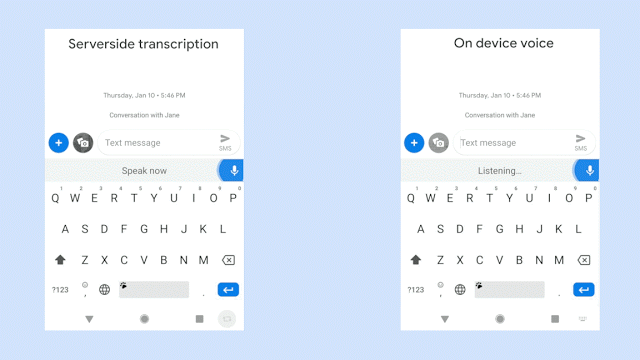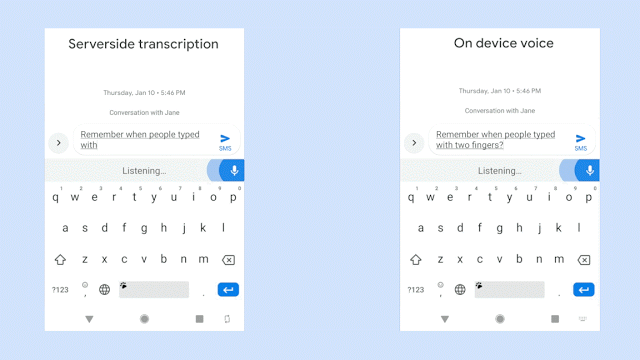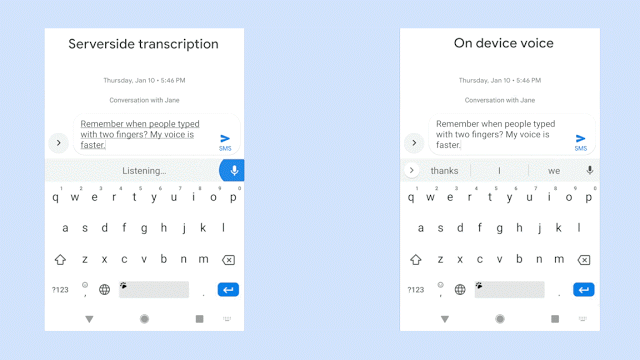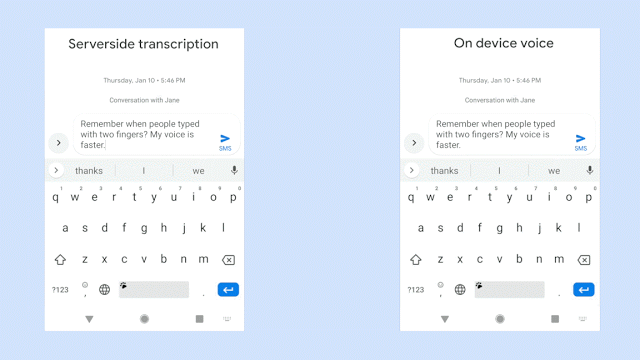
When Google first started development, the model used required a 2GB search graph. For many mobile phones, this is not an amount of storage that can be sacrificed just to support speech-to-text on a keyboard. After switching over to a recurrent neural network transducer from a more traditional approach, the file size was slashed down to 450MB.
Going further yet again, a 4x compression was applied along with some custom hybrid kernel techniques that are now available as part of the TensorFlow Lite library. After nearly five years of work, there is a mere 80MB model that can run in real time on just a single core.
