In context: The costs associated with AI model training have dropped more than 100 times between 2017 and 2019, yet they remain prohibitive for most startups to this day. This naturally favors large companies like Nvidia and Microsoft, who are using incredible amounts of engineering talent and money to create ever-larger and more capable AI models for use in natural language processing, enhancing search engine results, improving self-driving technology, and more. Scaling them up is the easy part -- quantifying and removing bias is a problem that has yet to be solved.

Nvidia and Microsoft on Monday revealed they have been working together on something called the “Megatron-Turing Natural Language Generation model.” The two companies claim they’ve created the world’s largest and most capable “monolithic transformer language model trained to date.”
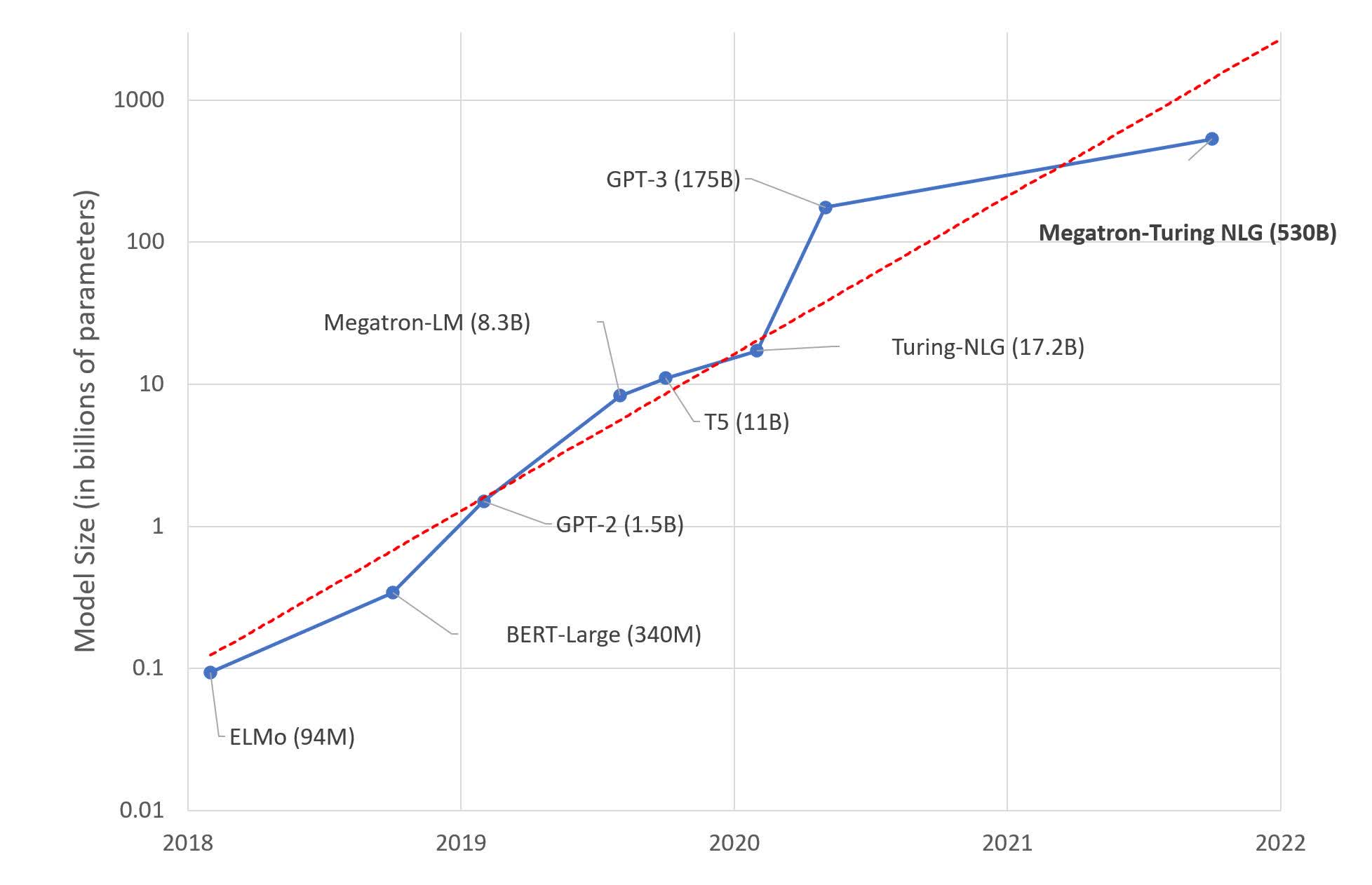
To get an idea of how big this is, the famous GPT-3 that’s been making the news rounds for the past few years currently has 175 billion parameters. By comparison, the new MT-NLG model spans 105 layers and has no less than 530 billion parameters.
MT-NLG is the successor to the Turing NLG 17B and Megatron-LM models and was able to demonstrate “unmatched accuracy” in a variety of natural language tasks such as reading comprehension, common sense reasoning, completion prediction, word sense disambiguation, and natural language inferences.

Image: Nvidia's A100 GPU
Nvidia and Microsoft have been training this gargantuan AI model on a supercomputer called Selene. This is a system comprised of 560 Nvidia DGX A100 servers, each holding eight A100 GPUs equipped with 80 gigabytes of VRAM connected via NVLink and NVSwitch interfaces. Microsoft notes this configuration is similar to the reference architecture used in its Azure NDv4 cloud supercomputers.
Interestingly, Selene is also powered by AMD EPYC 7742 processors. According to the folks over at The Next Platform, Selene cost an estimated $85 million to build — $75 million if we assume typical volume discounts for data center equipment.
Microsoft says MT-NLG was trained on 15 datasets containing over 339 billion tokens. The datasets were taken from English-language web sources, such as academic journals, online communities like Wikipedia and Stack Exchange, code repositories like GitHub, news websites, and more. The largest dataset is called The Pile and weighs in at 835 gigabytes.
| Dataset | Dataset Source | Tokens (billions) | Weight (percentage) | Epochs |
|---|---|---|---|---|
| Books3 | Pile dataset | 25.7 | 14.3 | 1.5 |
| OpenWebText2 | Pile dataset | 14.8 | 19.3 | 3.6 |
| Stack Exchange | Pile dataset | 11.6 | 5.7 | 1.4 |
| PubMed Abstracts | Pile dataset | 4.4 | 2.9 | 1.8 |
| Wikipedia | Pile dataset | 4.2 | 4.8 | 3.2 |
| Gutenberg (PG-19) | Pile dataset | 2.7 | 0.9 | 0.9 |
| BookCorpus2 | Pile dataset | 1.5 | 1.0 | 1.8 |
| NIH ExPorter | Pile dataset | 0.3 | 0.2 | 1.8 |
| Pile-CC | Pile dataset | 49.8 | 9.4 | 0.5 |
| ArXiv | Pile dataset | 20.8 | 1.4 | 0.2 |
| GitHub | Pile dataset | 24.3 | 1.6 | 0.2 |
| CC-2020-50 | Common Crawl (CC) snapshot | 68.7 | 13.0 | 0.5 |
| CC-2021-04 | Common Crawl (CC) snapshot | 82.6 | 15.7 | 0.5 |
| RealNews | RealNews | 21.9 | 9.0 | 1.1 |
| CC-Stories | Common Crawl (CC) stories | 5.3 | 0.9 | 0.5 |
Overall, the project revealed that larger AI models need less training to operate sufficiently well. However, the reoccurring problem that remains unsolved is that of bias. It turns out that even when using as much and diverse data from the real world as possible, giant language models pick up bias, stereotypes, and all manner of toxicity during the training process.
Curation can help to some extent, but it's been known for years that AI models tend to amplify the biases in the data that's being fed into them. That's because the data sets have been collected from a variety of online sources where physical, gender, race, and religious prejudices are quickly becoming a common occurrence. The biggest challenge in solving this is quantifying the bias, which is no small task and still very much a work in progress no matter how many resources are thrown at it.

Some of you may recall a previous Microsoft experiment where it unleashed a Twitter chatbot dubbed Tay. It only took a few hours for Tay to pick up all the worst traits that humans could possibly teach it, and the Redmond company had to take it down less than 24 hours after launch.
Nvidia and Microsoft both said they’re committed to addressing this issue and will do their best to support research in this direction. At the same time, they warn that organizations who want to use MT-NLG in production must make sure the proper measures are put in place to mitigate and minimize potential harm to users. Microsoft noted that any use of AI should follow the reliability, security, privacy, transparency, and accountability principles outlined in its "Responsible AI" guide.
