
Software developers at Microsoft have been working on a new method of automated testing. A technique called fuzzing relies on inputting mass amounts of data into a program to try and force a crash or unexpected behavior to occur so that an exploit can be found. In an effort to reduce vulnerabilities and improve software quality, neural fuzzing has been developed.
Traditional fuzzing tools fall into one of three categories. Blackbox fuzzers are unintuitive and use ready-made sample files to create new inputs. Whitebox fuzzers are much smarter compared to blackbox; a whitebox fuzzer will attempt to go down as many different branches of code as possible using an algorithm. Graybox fuzzers do not map the code structure of a program in the same ways that whitebox tools can, but contain a feedback loop to have better odds of finding an error using sample input.
Microsoft's new neural fuzzing project takes a graybox fuzzer and applies a deep neural network to the feedback loop. Over time, neural feedback helps to find significantly more unique code paths that could identify program flaws. In a test on a library for parsing .png files, Microsoft identified double the number of code paths using neural networks compared to traditional fuzzing techniques.
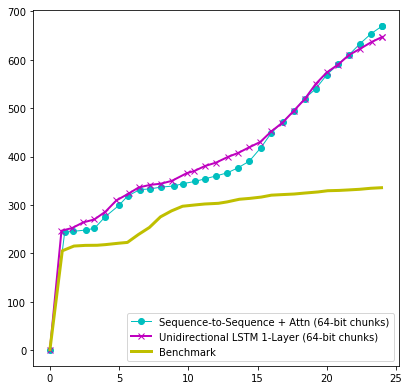
As with all technologies under research and development phases, there are still a few issues to work out. When attempting to run PDF files through the neural network, traditional methods still outperformed the neural network. Large file size causing slow response from the neural network was believed to the be culprit.
For those wondering if this new neural network will ever be accessible to the public, there is good news. Microsoft has already released a tool called Microsoft Security Risk Detection. Using Azure cloud services, anyone with some basic knowledge can use the tool to try and find bugs in software.
https://www.techspot.com/news/71898-microsoft-using-neural-fuzzing-find-new-software-exploits.html
