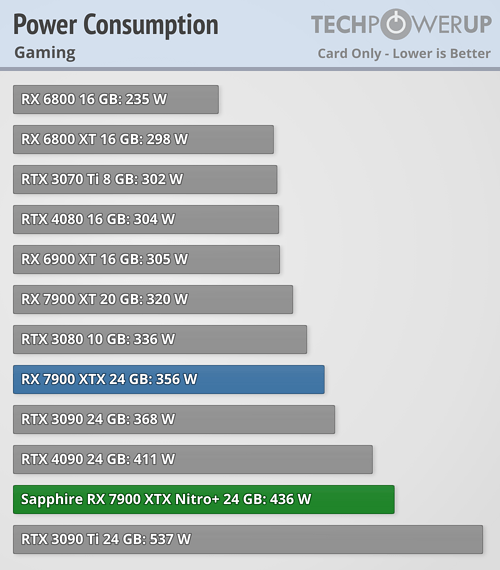
still, the die space they saved didn't allow them to have a 4090-equivalent card, cause of power draw that n31 requires already.
Don't forget that all of the Ada chips are on a custom N4 node -- there's obviously no details as to what this entails, but TSMC's
standard N4P process is 22% more power efficient than N5 (along with a small boost to performance and overall transistor density). Add in the fact that N6 is even less efficient, and the power cost for the GCD-MCD fabric, then it's no surprise that the Navi 31 chip is pretty hefty on the power consumption.
AMD needed to make its Gaming division more cost-effective and the only way to do that is by improving yields and operating margins. The former is certainly better than the Navi 2x and while it's not possible to tell exactly how much better Navi 3x is for the latter, the fact that the division has had a consistently positive operating margin for two years shows that something is working, at least.
The bulk of that sector's revenue comes from selling APUs to Microsoft and Sony, and the margins on those chips are likely to be very small. The division's mean margin is 16% (since inception) so AMD is getting a decent return on its GPUs.
Maybe doing it the same way as nvidia would require more die space indeed, but at the same time the performance advantage over rx6000 series would probably double.
It's just not AMD's way of doing things. Every update from RNDA through to RDNA 3 has involved relatively minor changes in the architecture -- the fundamental graphics core hasn't changed all that much.
One thing to perhaps note is that RDNA doesn't seem to scale as well as Nvidia's design, in terms of unit count. The Navi 10 was 40 CUs and that first card, on release, performed
around the same as a 2060 Super/2070, cards with 34 & 36 SMs respectively.
The Navi 31 has 96 CUs -- 2.4 times more than the Navi 10. Scale those Turing chips by the same level and one has a GPU with 82 to 86 SMs, in the region of 40 fewer than that in the 4090 (even more so for the full AD102). Using the same level of scaling from a 2060 Super to a 4090 on the Navi 31 would give it 150 or so CUs.
Of course, Ampere and Ada chips have two FP pipelines per SM partition, so the gain in processing is even greater. To make Navi in the same way would push the die size far too big and, to try and bring this back around to the topic of the article, this is also why AMD's gaming GPUs don't have large, complex ASICs for tensor calculations or BVH traversal acceleration.
In many ways, AMD is fortunate that Nvidia chose to uplift GPUs into higher SKU tiers than in previous generations and then charge a small fortune for them. They were always going to be more expensive due to using a custom, highest-level node available on the market, but if the 4080 used a 100 SM AD102, and the 4070 used the AD103, and so on, AMD's RDNA 3 product lineup wouldn't have looked half as good as it does.