In brief: OpenAI wants to create a general artificial intelligence (AGI) that benefits all of humanity, and that includes being able to understand everyday concepts and blend them in creative ways. The company's latest AI models combine natural language processing with image recognition and show promising results towards that goal.

OpenAI is known for developing impressive AI models like GPT-2 and GPT-3, which are capable of writing believable fake news but can also become essential tools in detecting and filtering online misinformation and spam. Previously, they've also created bots that can beat human opponents in games like Dota 2, as they can play in a way that would require thousands of years worth of training.
The research group has come up with two additional models that build on that foundation. The first called DALL-E is a neural network that can essentially create an image based on text input. OpenAI co-founder and chief scientist Ilya Sutskever notes that with its 12 billion parameters, DALL-E is capable of creating almost anything you can describe, even concepts that it would never have seen in training.

For example, the new AI system is able to generate an image that represents "an illustration of a baby daikon radish in a tutu walking a dog," "a stained glass window with an image of a blue strawberry," "an armchair in the shape of an avocado," or "a snail made of a harp."
DALL-E is able to generate several plausible results for these descriptions and many more, which shows that manipulating visual concepts through the use of natural language is now within reach.
Sutskever says that "work involving generative models has the potential for significant, broad societal impacts. In the future, we plan to analyze how models like DALL-E relate to societal issues like economic impact on certain work processes and professions, the potential for bias in the model outputs, and the longer-term ethical challenges implied by this technology."
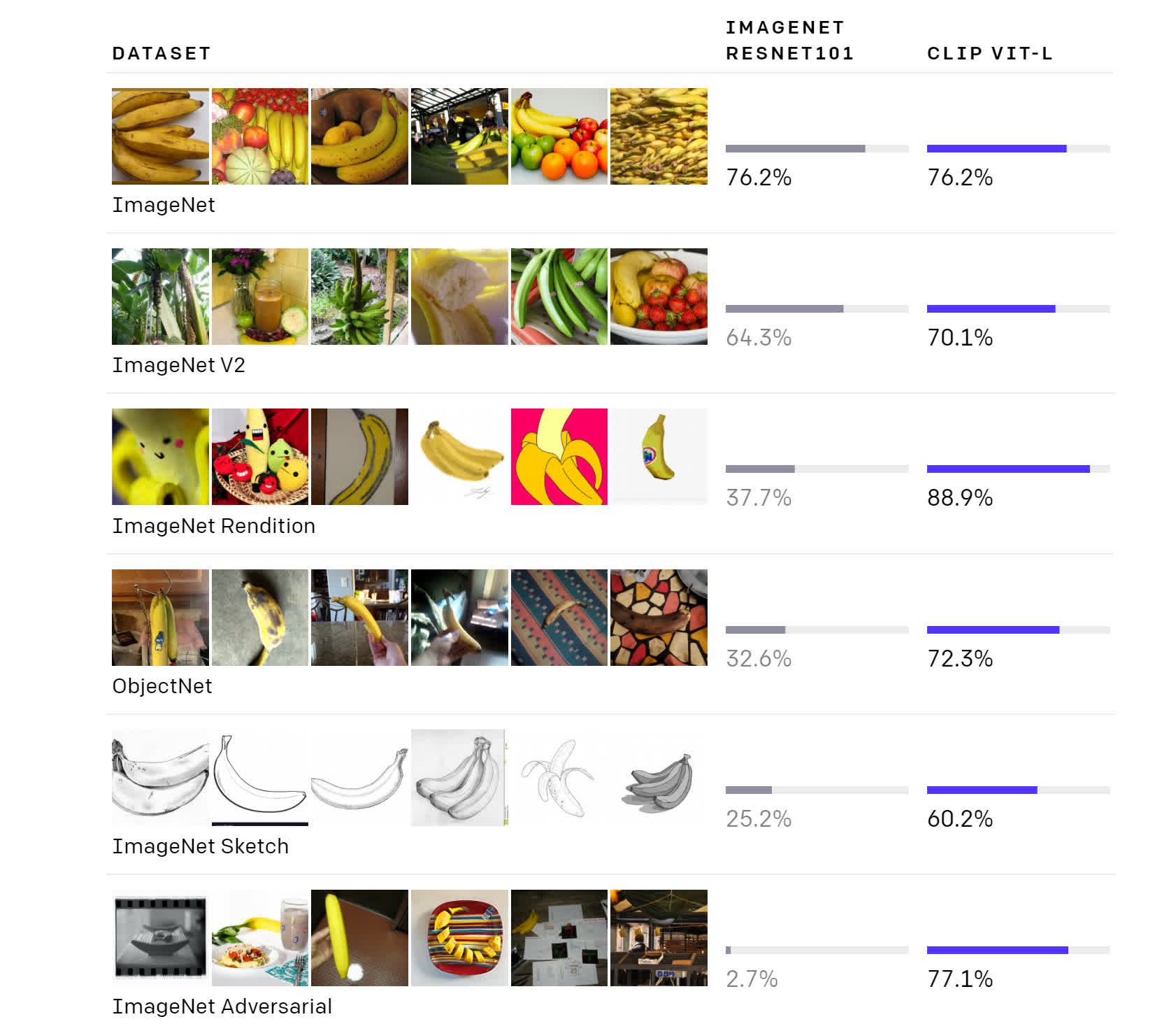
CLIP outperforms other models even on recognizing objects from more abstract visual representations
The second multimodal AI model introduced by OpenAI is called CLIP. Trained on no less than 400 million pairs of text and images scraped from around the web, CLIP's strength is its ability to take a visual concept and find the text description that's most likely to be an accurate description of it using very little training.
This can reduce the computational cost of AI in certain applications like object character recognition (OCR), action recognition, and geo-localization. However, researchers found it fell short in other tasks like lymph node tumor detection and satellite imagery classification.
Ultimately, both DALL-E and CLIP were built to give language models like GPT-3 a better grasp of everyday concepts that we use to understand the world around us, even as they're still far from perfect. It's an important milestone for AI, which could pave the way to many useful tools that will augment humans in their work.
https://www.techspot.com/news/88191-openai-dall-e-turns-weird-text-weird-images.html