TL;DR: Computer science researchers at the University of Edinburgh and Adobe Research have developed an AI that can be used to make video-game characters interact more naturally with their environments. The technique uses a deep neural network called a "neural state machine" or NSM to accurately animate a character by inferring its motions in a given scenario.
Back in the 8- and 16-bit days of video gaming, character animations were pretty rudimentary, with most games having static environments and limited interaction. Therefore, the avatar's movements did not require many different animations.
After the transition to 3D games, the tasks of animating became more complicated. Now that games have gotten vastly more complex with huge open-worlds to explore and interact with, animating in-game characters requires hundreds or even thousands of different movement skills.
One way to alleviate the tediousness of the animation process and make it faster is to use motion capture (mo-cap) to digitize the movements of actors into corresponding character animations. The result is in-game movements that look more realistic. However, it is virtually impossible to capture every possible way a player might interact with the environment.
Additionally, transitions between animations can look a little awkward and canned. Usually, changes between movements are handled by reused algorithms that run the same way every time. Think about how a character might sit down in a chair or set down a box. It get even more complicated when the objects vary in size. Resting its arms on chairs of different sizes or lifting objects of varying size and shape become cumbersome to animate.
In their paper, "Neural State Machine for Character-Scene Interactions," the team demonstrates the complexities of a given animation using the example of picking up an object. Before the item can even be lifted, several motions have to be considered and animated, including starting to walk, slowing down, turning around while accurately placing its feet, and interacting with the object. All of this occurs before the action of picking up the item.
The researchers refer to this as "planning and adaptation," and it is where deep learning begins to come into play.
"Achieving this in production-ready quality is not straightforward and very time-consuming," says PhD student and senior author of the paper Sebastian Starke (video above). "Our Neural State Machine instead learns the motion and required state transitions directly from the scene geometry and a given goal action. Along with that, our method is able to produce multiple different types of motions and actions in high quality from a single network."
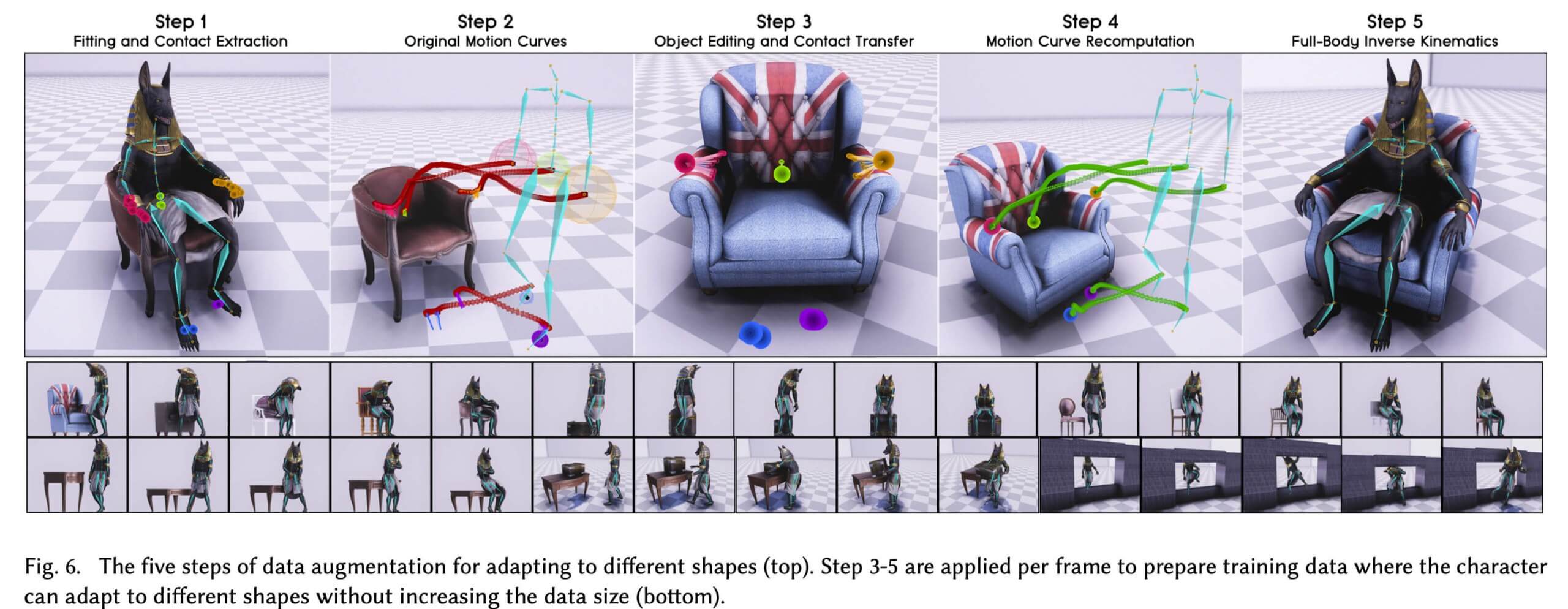
The NSM is trained using mo-cap data to learn how to transition from one movement to the next naturally. The network infers the character's next pose based both on its previous pose and on scene geometry.
For example, the animations of an avatar going through a doorway would be different if an object blocked the entrance. Instead of merely walking through, the character would have to skirt or step over the obstacle.
The framework the researchers have created allows users to move the character through environments with simple control commands. Additionally, it does not require the NSM network to retain all of the motion capture data. Once an animation is learned, the mo-cap is compressed and stored while keeping the learned behavior.
"The technique essentially mimics how a human intuitively moves through a scene or environment and how it interacts with objects, realistically and precisely," said the paper's co-author Taku Komura, who is chair of computer graphics at the University of Edinburgh.
The researchers intend to continue work on other related scenarios, such as naturally moving the character through a crowd or performing multiple actions simultaneously. Consider the repetitive and choppy movements navigating crowds in Assassin's Creed games.
The team will be presenting its current research at the ACM Transactions on Graphics / Siggraph Asia, held in Brisbane, Australia November 17 - 20.
https://www.techspot.com/news/82566-using-deep-learning-make-video-game-characters-move.html