
In context: Back in 2018, Apple yanked Nvidia support from macOS entirely, and that was pretty much it for CUDA on the platform. Developers who wanted GPU compute from Team Green on their Macs were out of luck for years. But that's now changing.
Tiny Corp, the same company that built the tinybox AI accelerator, has written its own Nvidia GPU driver completely from scratch. It's called TinyGPU, and it's an open-source macOS kernel extension. Better yet, Apple has signed off on it. That means you don't need workarounds like setting up a virtual machine or messing with System Integrity Protection to run it. All you need to do is plug in an external GPU over Thunderbolt or USB4, approve the extension, and it works.
One YouTuber has already tested the driver using his RTX 5090 with 32GB of VRAM. Alex Ziskind plugged the GPU into a Mac Mini M4 Pro, and it ran just fine. That's impressive considering this is Nvidia Blackwell silicon hooked up to Apple Silicon via a single cable.
But actual performance is a more complicated story. In an inference test using Llama 3.1 8B – a popular open-source AI model – the RTX 5090 managed roughly 7.48 tokens per second. Tokens per second is basically how fast an AI model can spit out its response, and that number isn't going to blow anyone away.
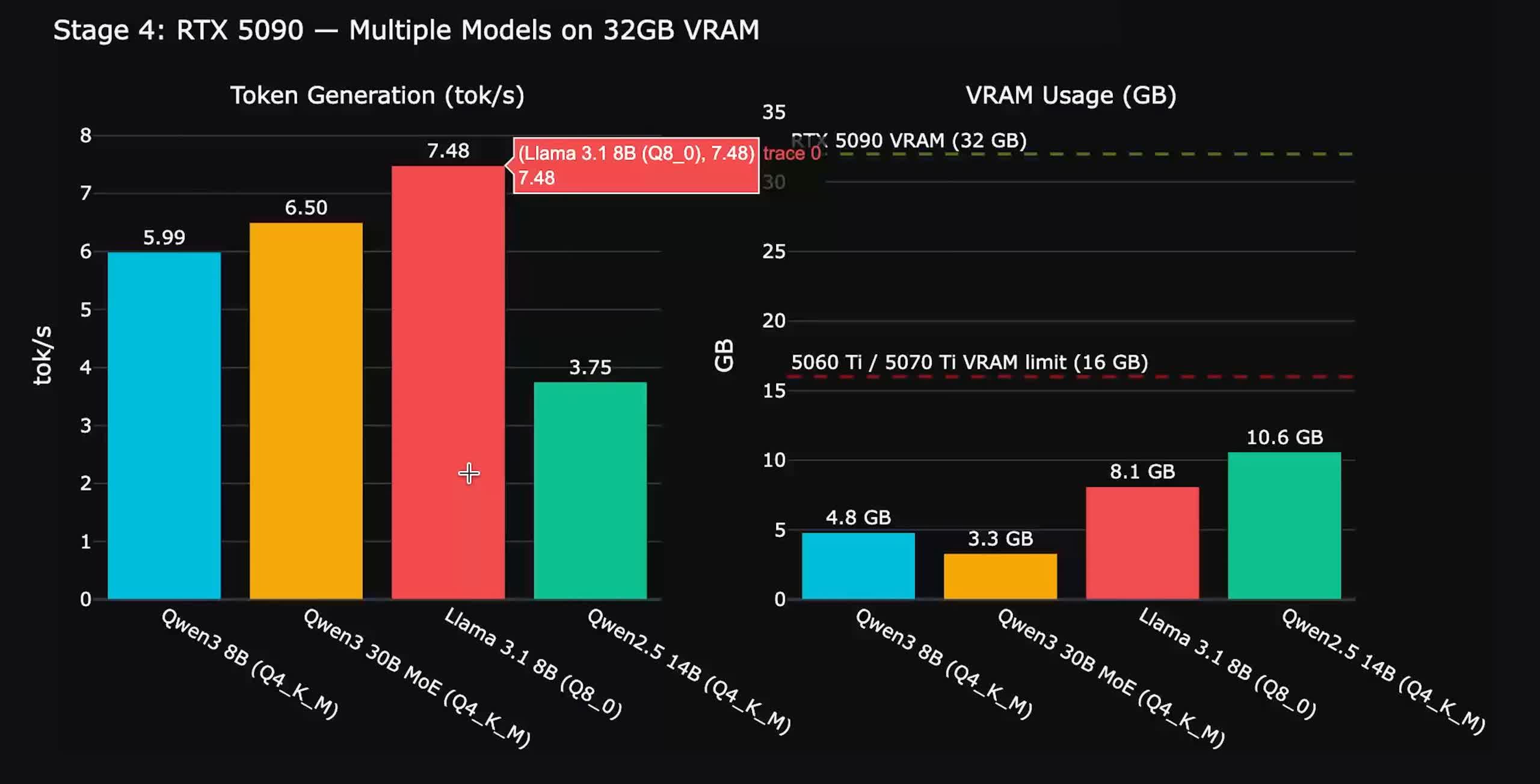
Where things did get interesting, though, was in chat-style tasks. Time to first token, which is how long you wait before the response even starts appearing, was three to four times quicker than what you'd get from using Metal natively. That made the experience feel noticeably snappy, according to Ziskind.
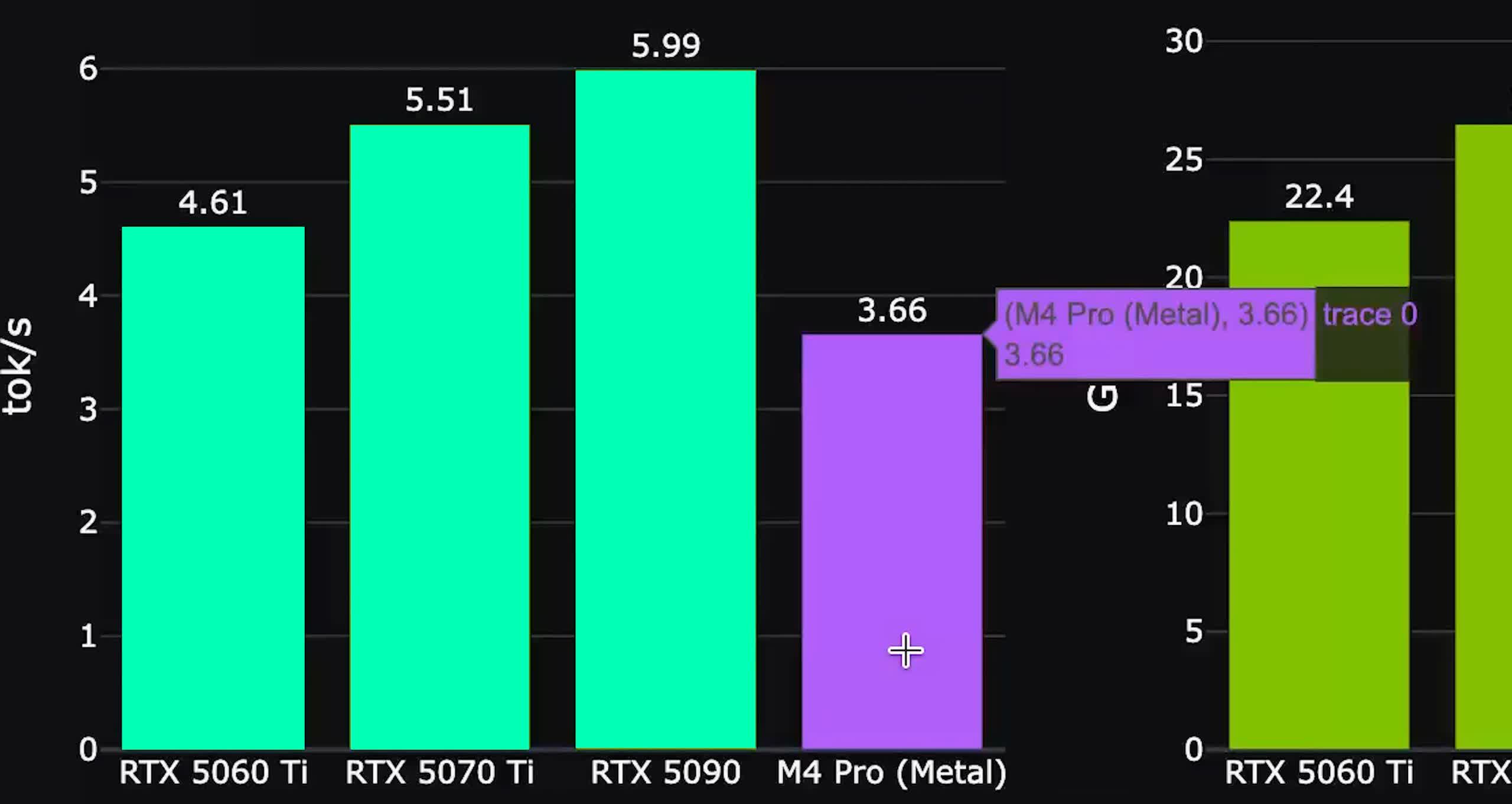
Now for the catch. Running llama.cpp, which is one of the most popular open-source tools for local AI inference, on Metal is still about ten times faster overall. That's a big gap, though it's not really a Thunderbolt bandwidth problem. According to Ziskind, the real culprit is kernel efficiency: the 5090's memory can do 1.8TB/s, but the driver is only reaching 33GB/s.
Then again, this isn't meant to compete with llama.cpp right now. The point is that the driver, compiler pipeline, and memory management are all in place. With that out of the way, Tiny Corp can start working on optimizations.