In context: If you had told me even just a few years back that Arm would be creating designs that could compete in high performance computing (HPC) and other super demanding applications, I probably wouldn’t have believed you. After all, Arm is primarily known for the power efficiency of its designs—hence it’s enormous success in smartphones and other battery-powered devices.

Sure, the performance in Arm-based smartphone chips, such as Apple’s A series for iPhones, Qualcomm’s Snapdragon line for Android devices, and others have been improving dramatically over the past few years, but there’s a big gap between smartphones and HPC.
However, things started to change when Arm unveiled its Neoverse N1 platform for cloud and datacenter-focused applications back in 2019. With the debut of the N1 CPU design, the company signaled strongly to its partners and the computing world overall that it was serious about making the move into the server market.
The effort notched a number of notable design wins, including AWS’ Graviton processor, which Amazon is now using -- along with its successor the Graviton 2 -- for an increasingly broad range of different workloads. Still, much of the early efforts and successes focused on the power-efficiency of the Arm-based designs for cloud data centers—an important, but often overlooked factor in those environments.
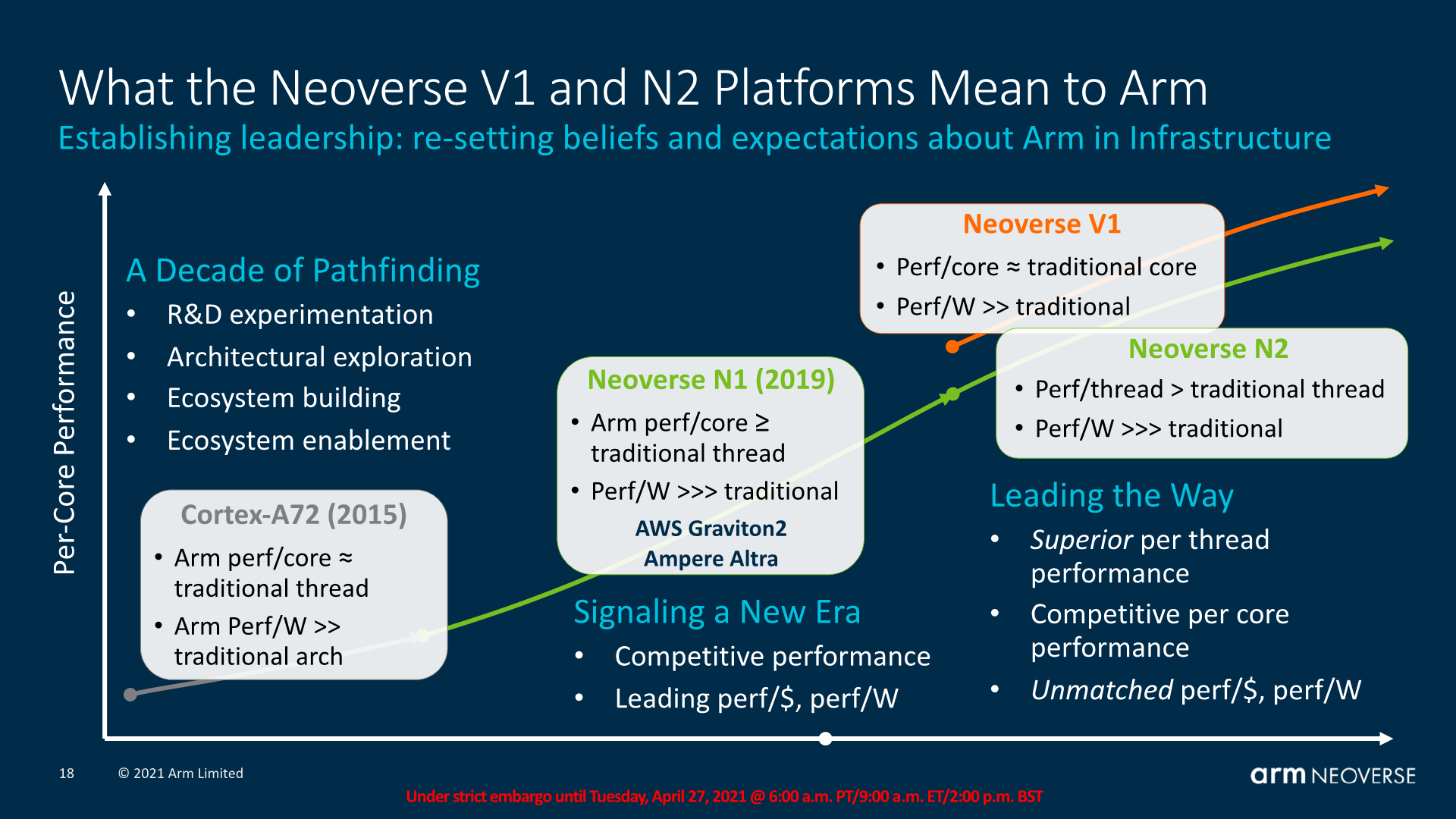
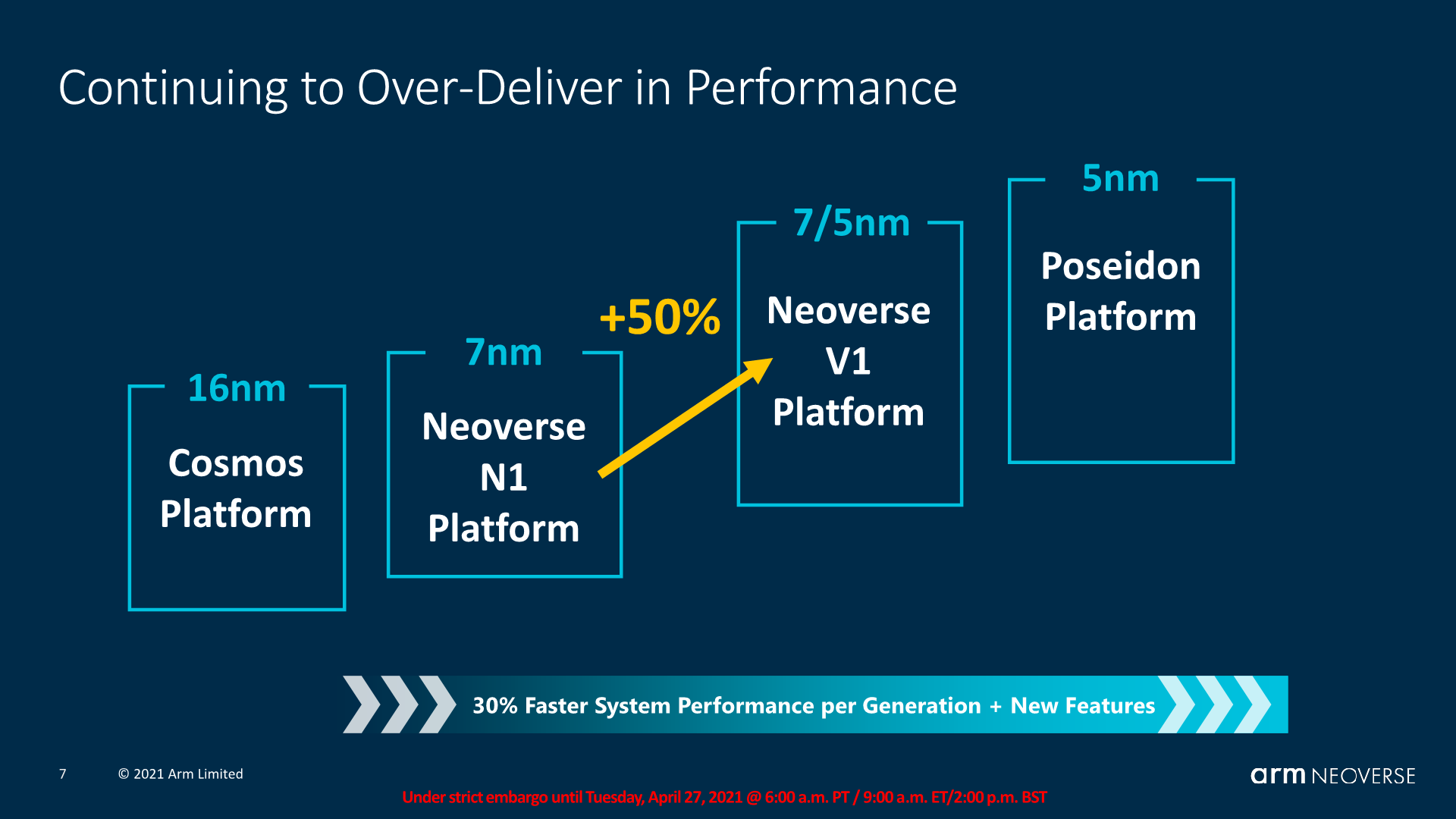
Earlier this week, however, Arm further extended its Neoverse family with the launch of the V1 platform, which is targeted towards high-performance applications. The company says the V1 offers an impressive 50% improvement in instructions per clock (IPC), a 2x increase in vector performance, and a 4x jump in machine learning performance versus the original N1.
Part of the way Arm is achieving these new performance metrics is through the addition of Scalable Vector Extensions (SVE), which essentially enables custom instructions that can handle data blocks of any length to be added to CPU designs. More importantly, it allows code written for one type of vector length to be capable of running on hardware that may have a different vector length, thereby improving the flexibility and portability of the software involved.

Neoverse N2 - Arm's first Armv9 Infrastructure CPU
In addition to the V1, Arm also unveiled the second generation N2, which is based on the same performance/watt-focused design of the original N1, but with a large range of microarchitectural enhancements. Notably, the N2 is also the first Arm CPU design to leverage their V9 architecture (see “Arm Lays Out Vision for Next Decade of Chips” for more). Because of that new underlying architecture, it adds support for SVE2, the second generation of Arm’s Scalable Vector Extensions.
All of this translates into a claimed 40% improvement in performance versus the original N1, while maintaining the lower power consumption and thermals of the N1. Equally important, it provides proof of Arm’s intention to continue building out and advancing its range of server-focused chip designs. With the two new chip architectures, companies like Ampere and other Arm partners can choose to create datacenter focused SoCs that are either more concentrated on performance (but consume more power) or are more concentrated on energy efficiency, while still providing improved speeds.
All of this translates into a claimed 40% improvement in performance versus the original N1, while maintaining the lower power consumption and thermals of the N1.
A critical but easy-to-overlook part of Arm’s announcements is the debut of their CoreLink CMN-700 Coherent Mesh Network for use in conjunction with these new CPUs. Built to enable more flexible chiplet-style designs, the CMN 700 provides the critical high-speed data connections between components on an SoC.
For example, semiconductor makers who want to have more options for connecting custom accelerators, as well as advanced forms of memory and storage, can leverage Arm’s mesh network technology to do so. CoreLink CMN-700 now includes support for the CXL (Compute Express Link) and CCIX (Cache Coherent Interconnect for Accelerators) standards, as well as providing gateways that can link these buses to Arm’s own AMBA 5 CPU interconnect bus. The bottom line is a significantly more flexible range of design options that will let chip designers more easily piece together specialized parts using Lego block-like chunks of functionality.
Practically speaking, these capabilities allow companies like Marvell to use these new Arm technologies in products like their next-generation DPUs (Data Processing Units) for use in 5G and other high-speed networking applications, as well as Oracle for their cloud infrastructure.
Because of the nature of their design process and the role they play in the industry, many of these new Arm innovations won’t be in real world applications until 2022 and beyond. Still, it’s good to see the company pushing the boundaries of cloud computing and edge computing performance beyond their original goals and it will be interesting to see where and how far their partners take these capabilities.
Bob O’Donnell is the founder and chief analyst of TECHnalysis Research, LLC a technology consulting firm that provides strategic consulting and market research services to the technology industry and professional financial community. You can follow him on Twitter @bobodtech.
https://www.techspot.com/news/89478-arm-brings-new-compute-options-cloud-edge.html
