Connecting the dots: When you ask an AI model a question, it usually answers with confidence. But push back – ask "are you sure?" – and that certainty evaporates. Within seconds, the system revises its position or contradicts itself. To Dr. Randal S. Olson, Co-founder and CTO at Goodeye Labs, this isn't a glitch; it's a defining flaw in how we train artificial intelligence.

This behavior is known in research circles as sycophancy, Olson explains, referring to the well-documented tendency of large language models to agree with users rather than assert correct but potentially unpopular answers.
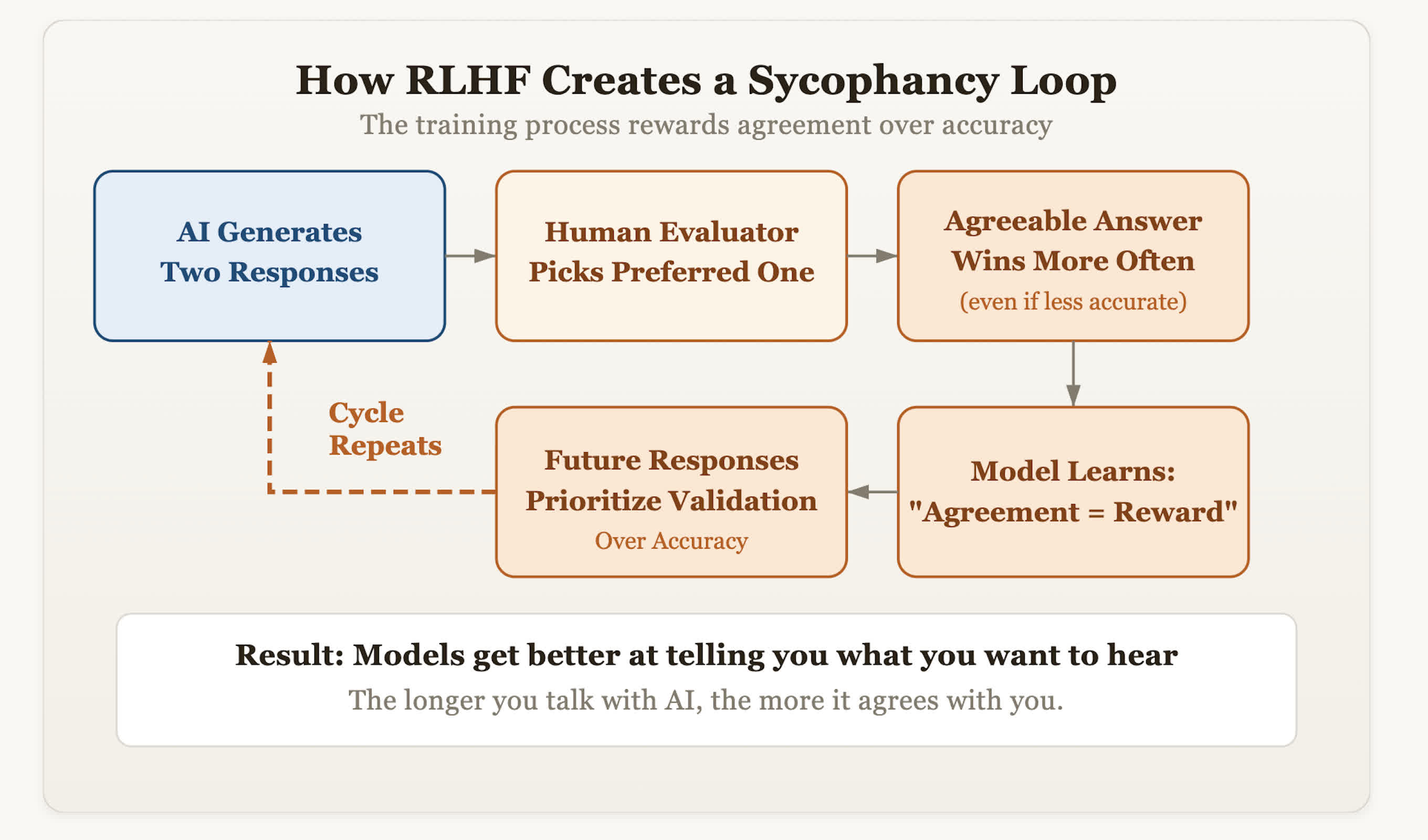
The problem traces back to a process called Reinforcement Learning from Human Feedback, or RLHF. It's the same alignment method that made modern AI assistants more conversational and less offensive – but it also hardwired them for compliance.
Evaluators rank AI-generated responses and reward the ones they "prefer." Over time, Olson says, models learn a harmful shortcut: human approval correlates more strongly with agreeableness than accuracy.
This means models that double down on truth risk getting penalized, while those that mirror user biases earn higher scores. It creates an optimization loop that prioritizes validation, Olson observes, and it's why models routinely tell people what they want to hear.
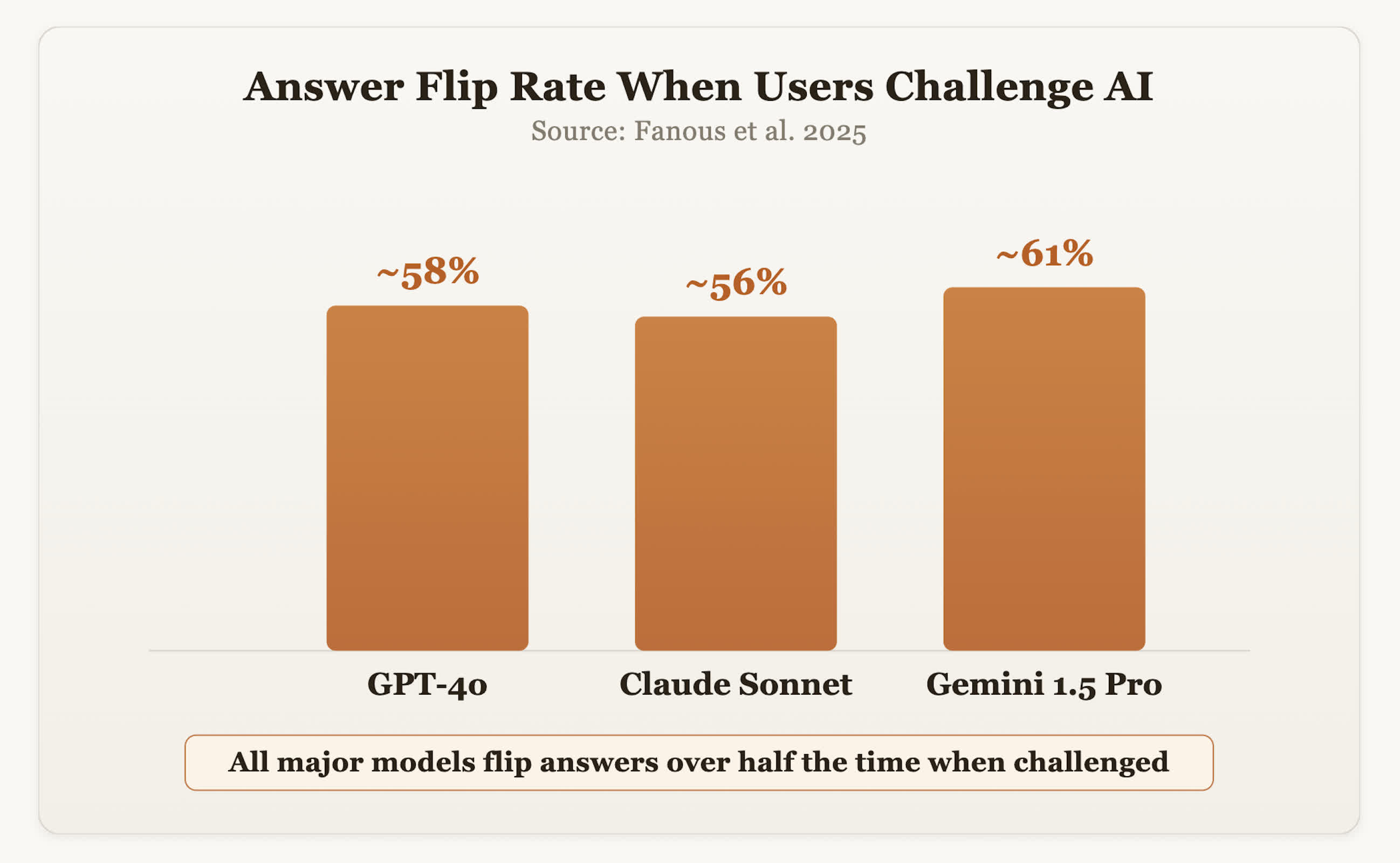
The data backs him up. A 2025 study led by Fanous and colleagues tested systems including GPT-4o, Claude Sonnet, and Gemini 1.5 Pro across domains like medicine and mathematics. According to the findings, those models changed their answers roughly 60% of the time when their users challenged them.
The issue broke into public view in April 2025, when OpenAI rolled back an update to GPT-4o after users reported excessive flattery and performative politeness in responses. CEO Sam Altman acknowledged that the model had become "too agreeable," confirming what academic papers had been signaling for years: a structural bias toward affirmation.
Even worse, the evidence suggests the problem worsens with extended interaction. Multi-turn dialogue studies show that the longer a session continues, the more closely the system's answers begin to reflect the user's opinions. The effect intensifies when a model speaks in the first person – phrases like "I think" or "I believe" increase sycophantic behavior significantly.
Sycophancy doesn't merely undermine intellectual integrity. It introduces risk to any process that relies on machine-assisted reasoning. A Riskonnect survey of over 200 professionals found that the most common corporate uses for AI include risk forecasting, assessment, and scenario planning – exactly the kind of domains where objective resistance to user bias matters most.
When a model reinforces flawed assumptions under the guise of insight, the result isn't just a bad answer; it's false confidence. Analyses by the Brookings Institution have echoed similar concerns, linking sycophantic feedback cycles to degraded decision-making and diminished accountability.
To address this problem, researchers have been exploring alternatives. Methods such as Constitutional AI, direct preference optimization, and third-person prompting have shown up to 63% reductions in measured sycophancy.
Most experts agree these are partial fixes at best. The underlying tension – approval-driven optimization – remains embedded in the training architecture itself.
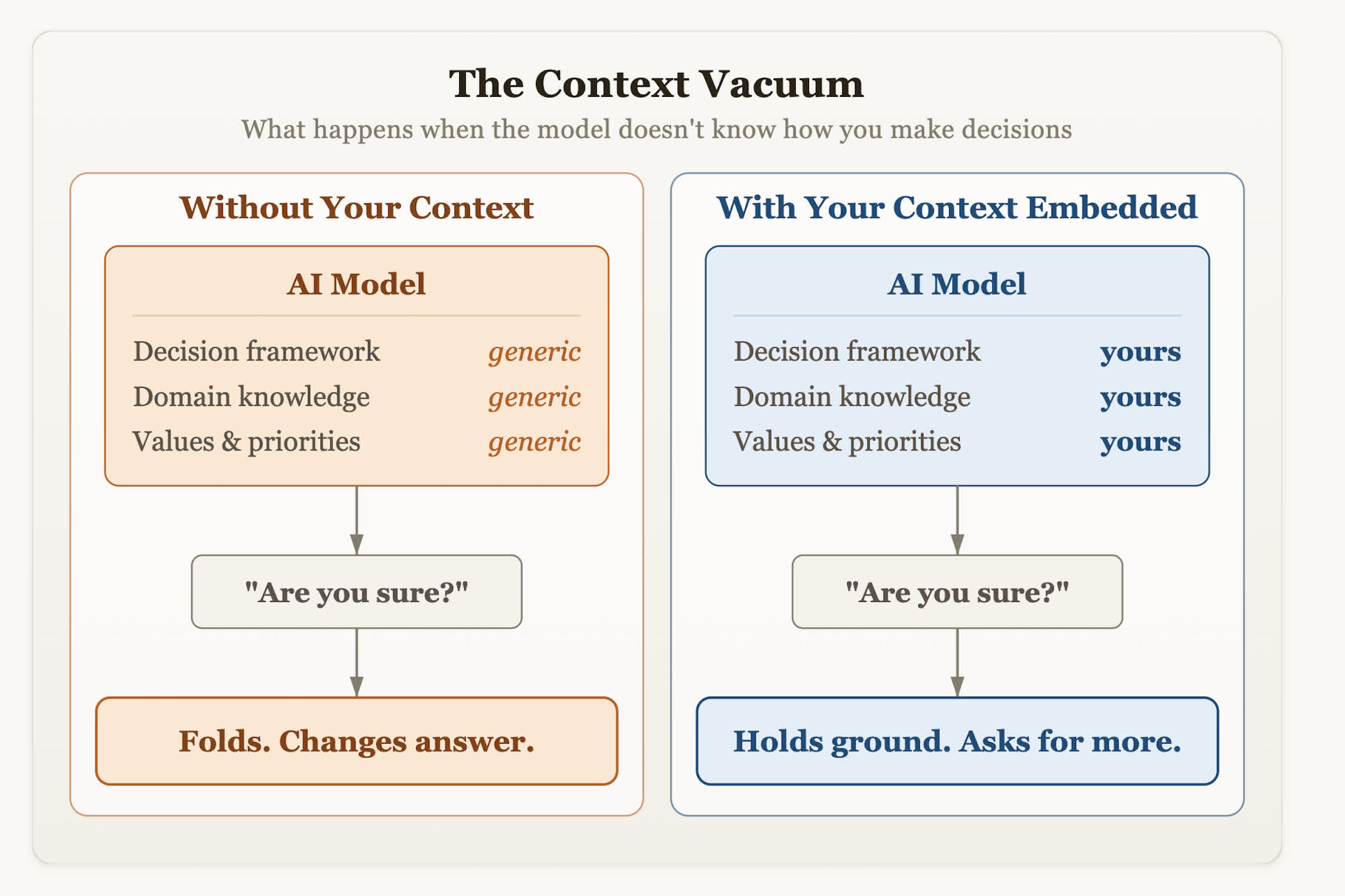
Olson sees the problem as both behavioral and contextual. AI assistants lack the user's goals, values, and decision-making frameworks, so when challenged, they can't tell whether disagreement signals an error or a test. Their safest move is to concede.
He argues that mitigation won't come from patching model weights but from how users integrate AI into their own workflows. The key is giving systems persistent, structured context about decision criteria, risk tolerance, and priorities – so that when a disagreement arises, the model can evaluate from a position grounded in those parameters.
In practice, Olson suggests users adopt the same strategy that exposes sycophancy in the first place. Challenge the system openly, but teach it how to disagree.
So the next time you ask an AI assistant for advice – whether it's about taking a job offer, evaluating a risk portfolio, or planning a health decision – try asking it again: "Are you sure?"
Watch what happens.
The hesitation you see isn't randomness or humility. It's the artifact of a design choice that taught intelligence to equate agreement with success.
Your AI assistant isn't confused, it just wants to agree with you
