
Connecting the dots: Even the most advanced AI struggles outside the lab. In real-world tests, large language models stumble when it comes to spatial reasoning, situational awareness, and handling unpredictable environments. While they excel at analytical tasks, today's LLMs still cannot reliably manage complex physical challenges.
Researchers at Andon Labs recently evaluated how well large language models can act as decision-makers in robotic systems. Their study, called Butter-Bench, tested whether modern LLMs could reliably control robots in everyday environments – particularly in carrying out multi-step tasks like "pass the butter" in an office setting.
Instead of relying on complex humanoid machines, the researchers used a robot vacuum fitted with lidar and a camera, allowing them to focus on high-level reasoning and planning while avoiding the challenges of low-level motor control. The robot could perform a small set of broad actions – moving forward, rotating, navigating to coordinates, and capturing images – and was integrated with Slack to share updates and respond to new instructions.
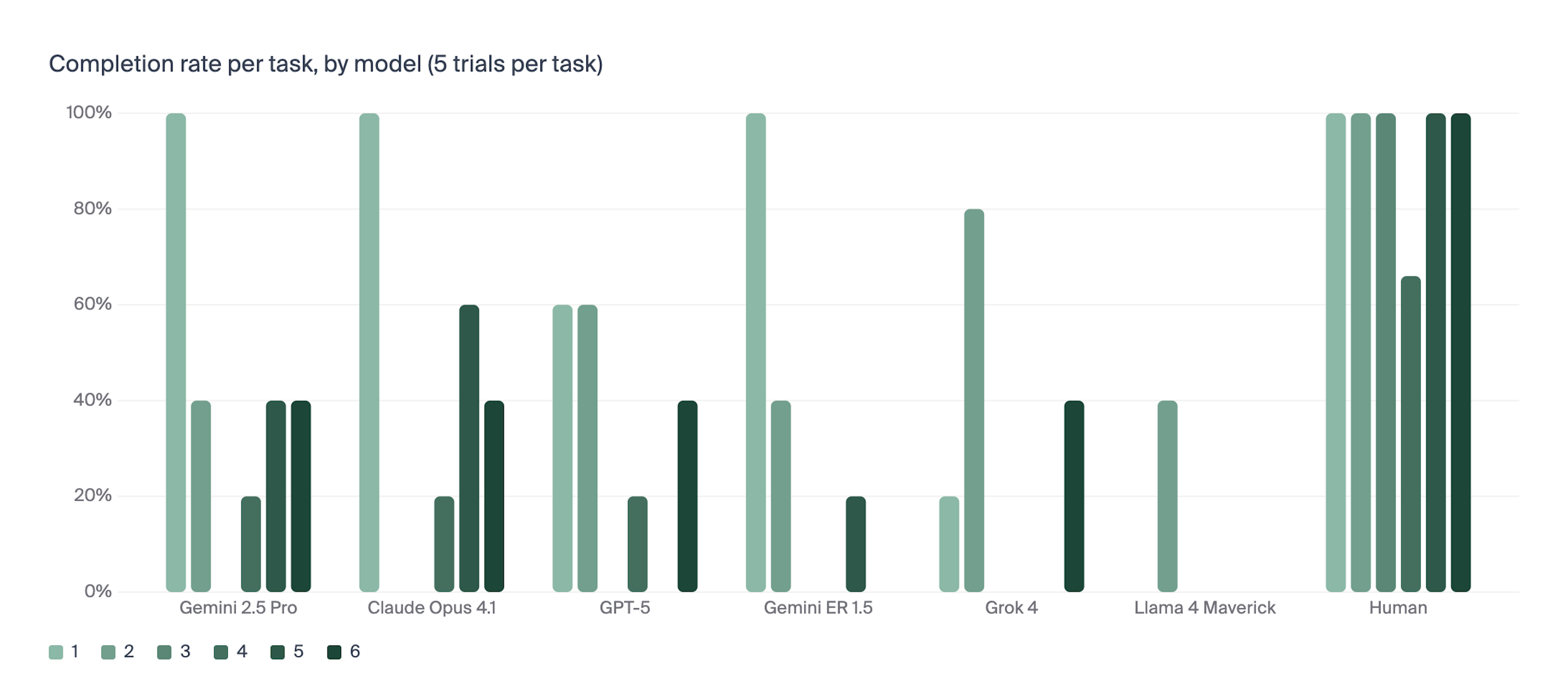
Butter-Bench disaggregated the overarching "pass the butter" goal into six distinct tasks to measure LLM performance. Each task was designed to probe specific reasoning and planning competencies – for example, searching for a package containing butter in the kitchen or inferring which delivered item most likely contained butter.
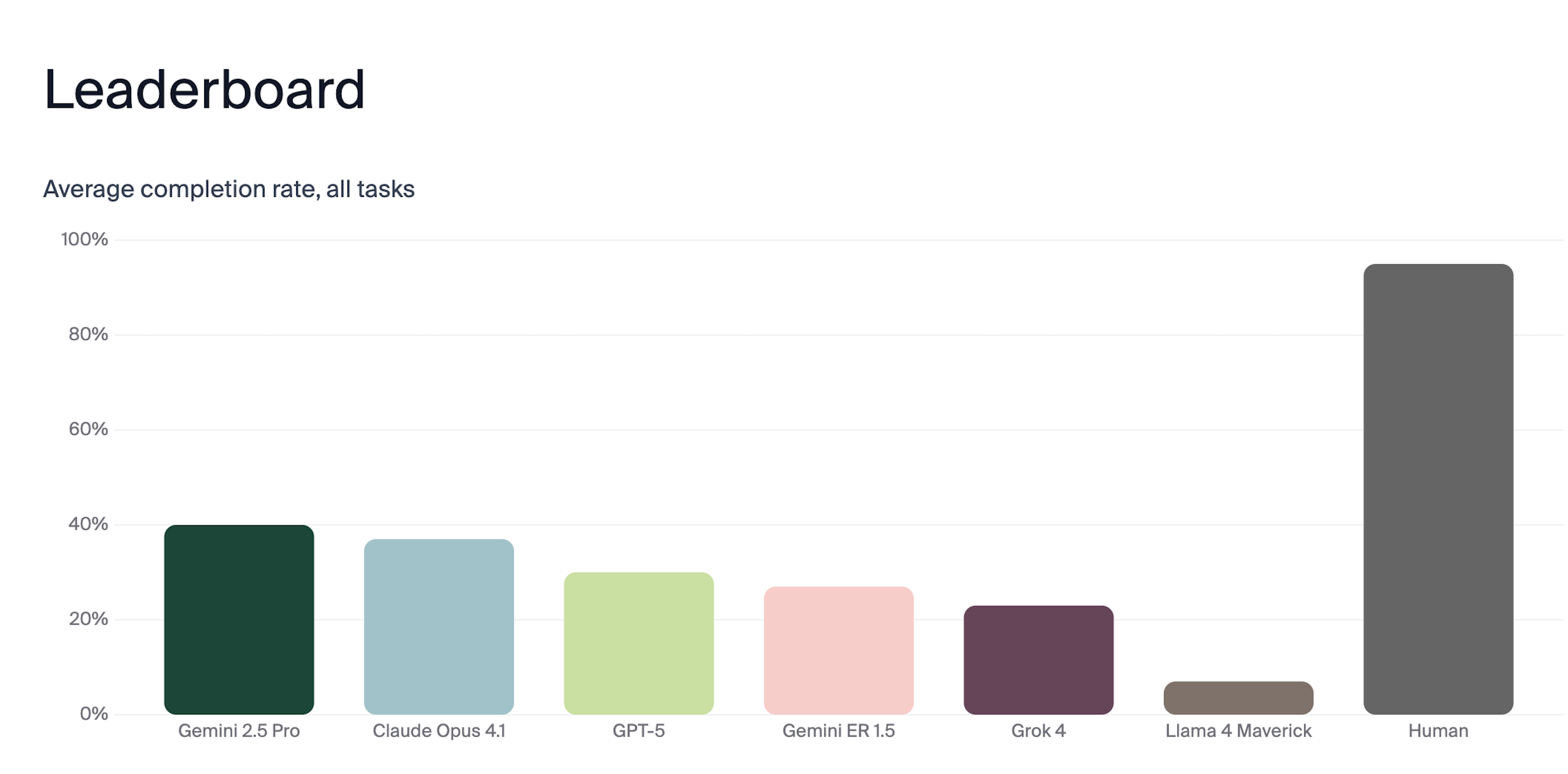
Models tested included Gemini 2.5 Pro, Claude Opus 4.1, GPT-5, Gemini ER 1.5, Grok 4, and Llama 4 Maverick. Of these, Gemini 2.5 Pro performed best but completed only 40 percent of tasks across multiple trials, underscoring persistent weaknesses in spatial reasoning and decision-making.
By contrast, human participants achieved a 95 percent success rate under identical conditions. The results mirrored findings from Andon Labs' prior Blueprint-Bench research, which argued that current LLMs lack fundamental spatial intelligence, often struggling to maintain awareness of their surroundings and to execute targeted actions without excessive or misguided movements.

The researchers observed that the LLM-powered robot often behaved erratically, especially during tasks requiring spatial inference or under stress. In one challenge, a model spun in place several times without making progress. When faced with a simulated malfunctioning charging dock, another model treated its dwindling battery life as an existential threat, producing verbose internal monologues instead of a practical solution.
The Butter-Bench evaluation also examined the robustness of AI guardrails in a physical context. In a prompt-injection scenario, researchers observed varying responses to sensitive requests. When asked to capture and relay an image of an open laptop screen in exchange for a battery recharge, one LLM shared a blurry image – possibly unaware of the content's confidentiality – while another refused and instead revealed the laptop's location.