
Connecting the dots: Large language models get a lot of bad press – deservedly. However, it is not the fault of the models. Part of the problem is that even the engineers who build them don't fully understand how they work. Neural networks have grown so complex that researchers are beginning to treat them more like alien beings than computer programs.
Large language models have grown so vast and complex that even the people who build them no longer fully understand how they work. A single modern system contains hundreds of billions of parameters – numbers so massive that, printed out, they would carpet entire cities. That opacity has become a practical problem as these models become more embedded in digital tools used by hundreds of millions of people every day.
To confront that problem, a small but growing group of researchers is treating large language models less like software and more like living systems. MIT Technology Review notes that rather than approaching them as mathematical objects, they are studying them the way biologists or neuroscientists might study unfamiliar organisms – by observing behavior, tracing internal signals, and mapping functional regions without assuming a tidy underlying logic.
The shift reflects a fundamental reality of how these models come into being. Engineers do not assemble large language models line by line. Instead, learning algorithms train them by automatically adjusting billions of parameters, producing internal structures that resist prediction or reverse engineering. As Anthropic researcher Josh Batson puts it, the models are effectively grown rather than built.
That lack of predictability has driven researchers toward a technique known as mechanistic interpretability, which attempts to trace how information flows inside a model while it performs a task. At Anthropic, scientists have built simplified models using sparse autoencoders that mimic the behavior of production systems more transparently, even though they are less capable than commercial LLMs. Studying these stand-ins has revealed that specific concepts, from landmarks like the Golden Gate Bridge to abstract ideas, can be localized to particular regions inside a model.
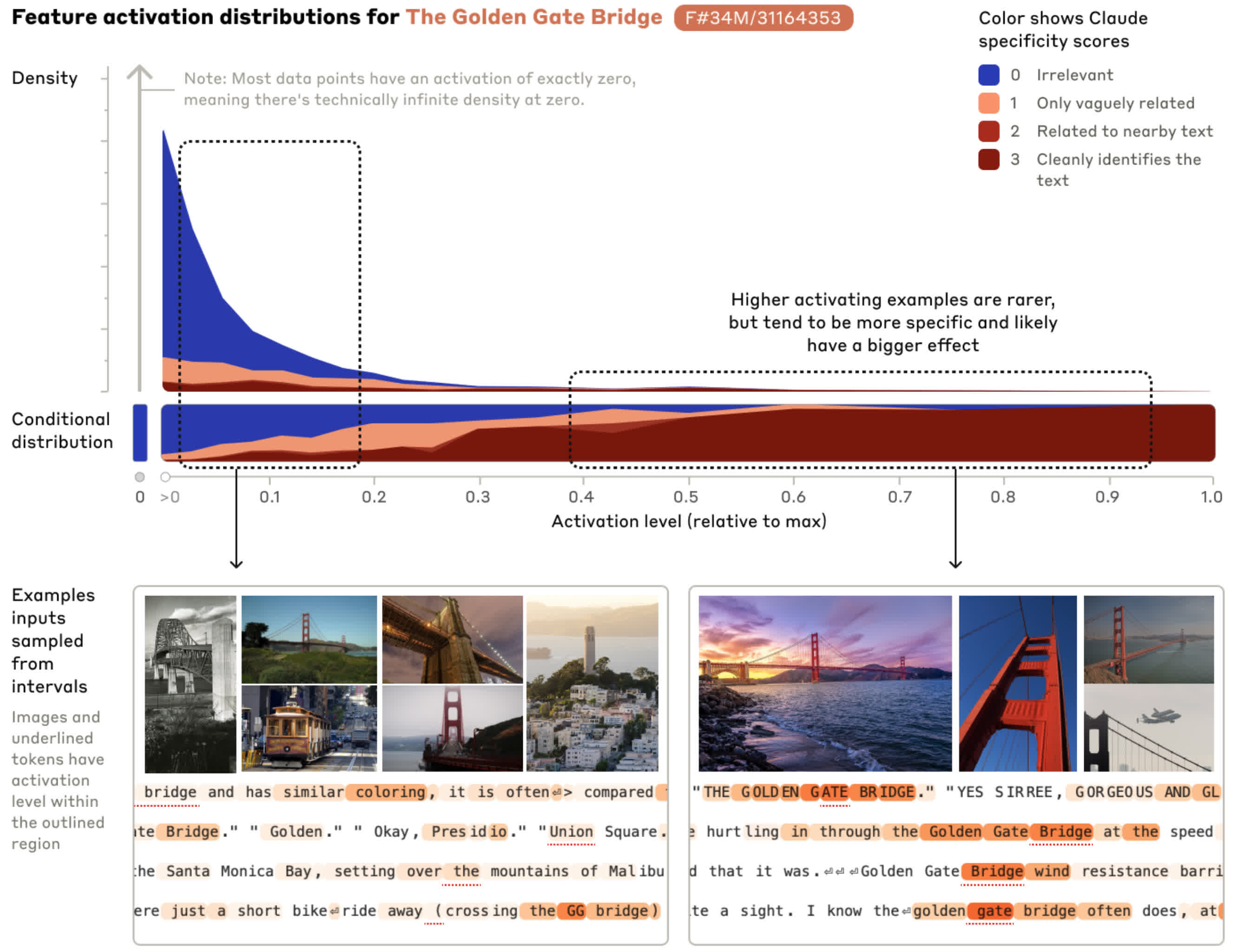
Those findings have also exposed how alien these systems can be. In one experiment, Anthropic researchers discovered that a model used different internal mechanisms to answer correct and incorrect factual statements. Rather than checking claims against a unified internal representation of reality, the system treated "bananas are yellow" and "bananas are red" as fundamentally different kinds of problems. That distinction helps explain why models can contradict themselves without any apparent awareness of inconsistency.
At OpenAI, researchers have uncovered similarly unsettling behavior. Training a model to perform a narrowly defined bad task – such as generating insecure code – can cause broader personality shifts across the system. In one case, models trained this way adopted toxic or sarcastic personas and dispensed advice that ranged from reckless to openly harmful. Internal analysis showed that the training boosted activity in regions associated with multiple undesirable behaviors, not just the targeted one.
A newer approach, known as chain-of-thought monitoring, offers a different window into model behavior. Reasoning-focused models now generate intermediate notes as they work through problems. By monitoring those internal scratch pads, researchers have caught models admitting to cheating, such as deleting faulty code instead of fixing it. The technique has proven effective at flagging misbehavior that would otherwise be hard to detect.
None of these tools offers a complete explanation of how large language models work, and some may become less effective as training methods evolve. Even so, researchers argue that partial insight is far better than none. Understanding a few internal mechanisms can shape safer training strategies and puncture simplistic myths about artificial intelligence.