
Forward-looking: Intel is pitching a new way to pack game textures that leans heavily on neural networks but still nods to traditional block compression. The company's Texture Set Neural Compression, or TSNC, is designed to sit on top of BC1-style schemes rather than replace them, trading extra math for more aggressive size reduction while trying to keep artifacts under control.
TSNC is being positioned as a practical path for developers who already ship BC-compressed assets and want to squeeze more data into the same storage, bandwidth, or VRAM budgets without rethinking their pipelines.
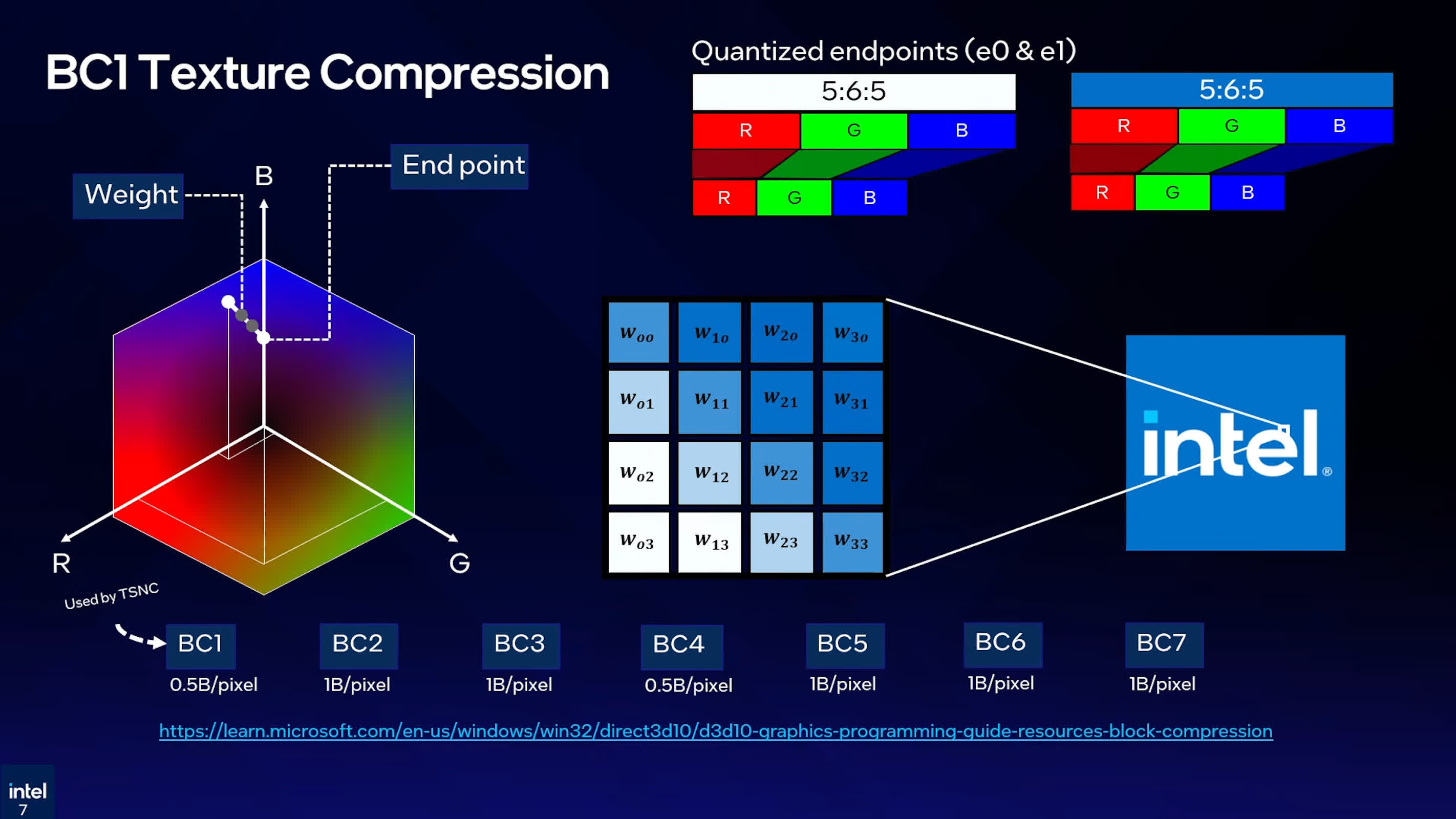
Instead of compressing each texture independently, TSNC trains a neural network on a set of related textures and then encodes them into a shared latent space. Intel stores that latent representation across four BC1-compressed pyramid levels and uses a three-layer MLP to rebuild the texture channels.
The company says the technique can be used at several points in the life of a game, from install and load to streaming and per-pixel sampling, depending on whether teams are chasing smaller installs, lower bandwidth, or reduced VRAM use. TSNC targets both disk footprint and on-the-fly shading costs rather than focusing solely on one metric.

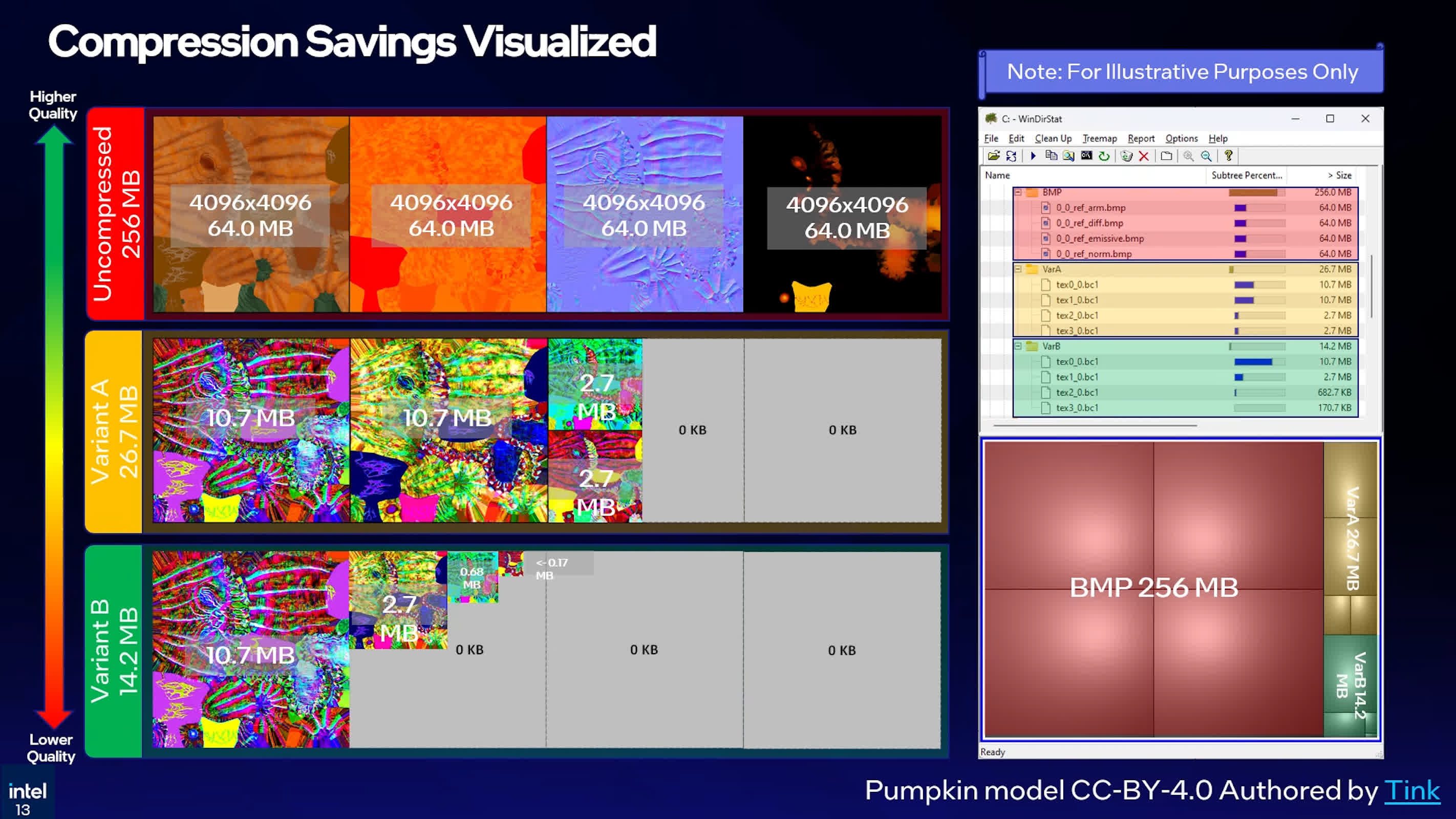
Intel is currently working on two TSNC modes. Variant A is tuned for higher quality, while Variant B pushes compression ratios further. In Intel's internal tests, standard BC compression produced about a 4.8x ratio versus the bitmap control set, whereas TSNC Variant A reached more than 9x compression.
Variant B went further, reaching more than 18x compression, or roughly double the size reduction of both Variant A and standard block compression in that comparison. Those numbers come with the usual caveats about content and settings, but they illustrate the headroom Intel sees from treating a whole texture set as one optimization problem.
That additional compression does introduce trade-offs. Intel reports that Variant A shows some precision loss in normals, while Variant B begins to show BC1 block artifacts in normals and ARM data.
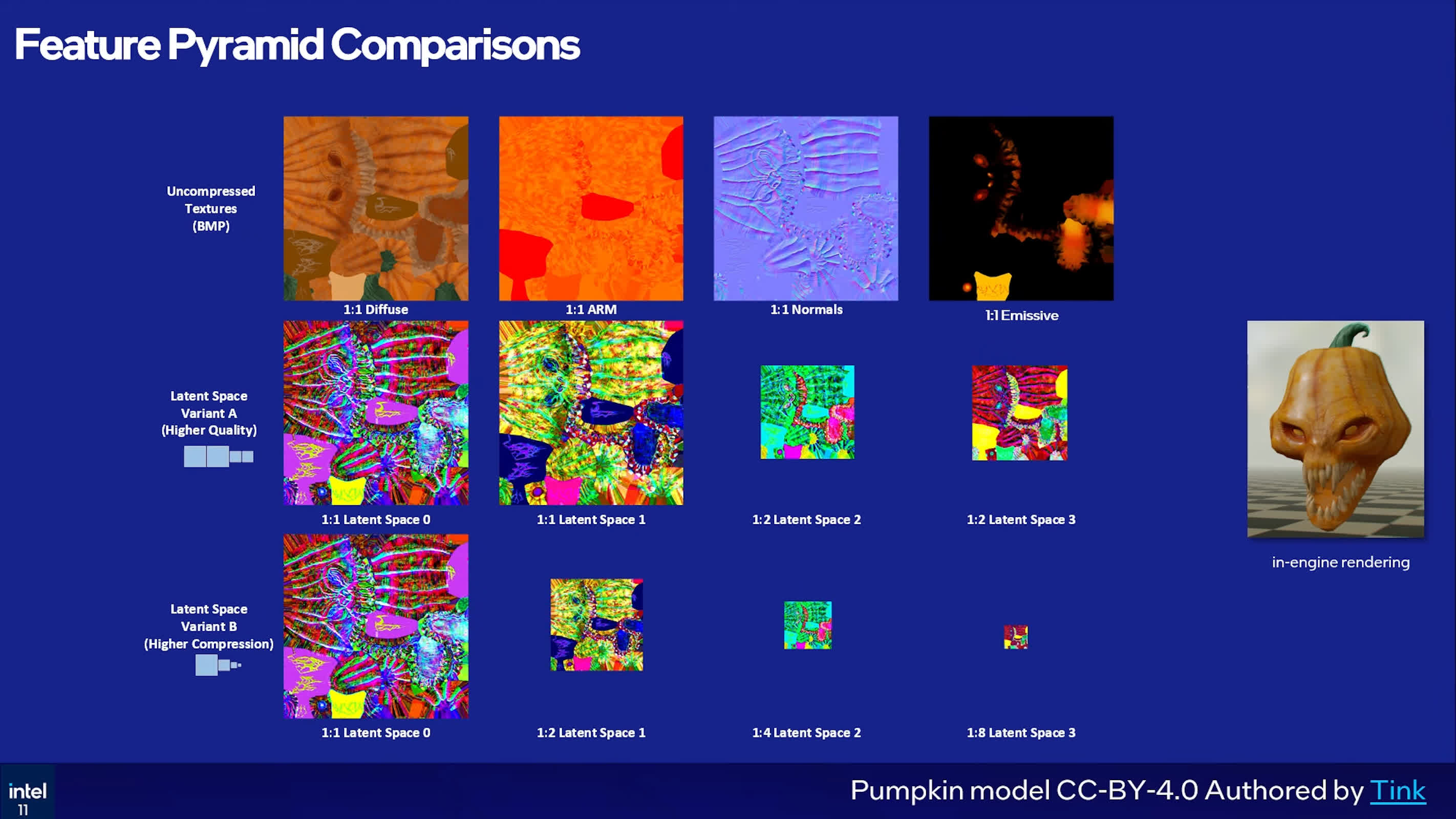
Using Nvidia's FLIP perceptual analysis tool, the company estimates around 5% perceptual loss for Variant A and roughly 6% to 7% for Variant B. In Intel's examples, Variant A is presented as the more balanced choice, with Variant B framed as the higher-compression, more artifact-prone option.
On the hardware side, Intel has shown TSNC running on upcoming Panther Lake integrated graphics using a new decompression API that can target C, C++, or HLSL. The decoder supports two execution paths: a fallback fused multiply-add route for CPUs and GPUs, and a linear algebra path that taps XMX acceleration on supported Intel GPUs.
In a Panther Lake microbenchmark on the integrated B390 GPU, Intel measured about 0.661 ns per pixel on the FMA path versus 0.194 ns per pixel on the XMX path, roughly a 3.4x gain. Intel stresses that TSNC is not only about shrinking textures on disk but also about demonstrating a viable runtime path for future Intel GPUs with XMX support.
TSNC arrives in a landscape where other vendors are also exploring neural texture compression.
Nvidia, for example, has discussed similar work and has mentioned compression ratios of up to 85%. Intel plans to release TSNC as a standalone SDK, with an alpha slated for later this year, followed by a public release at a later time.