
Bottom line: The world's most advanced AI systems struggle when confronted with the messy unpredictability of the real world, according to new research that tested leading models on one of Britain's favorite data-rich sports: soccer.
London-based AI start-up General Reasoning found that cutting-edge systems from Google, OpenAI, Anthropic, and Elon Musk's xAI consistently lost money when tasked with forecasting Premier League match outcomes over the 2023-24 season. The findings reveal how even top-tier frontier models still falter in dynamic environments, despite achieving rapid progress in static tasks like coding.
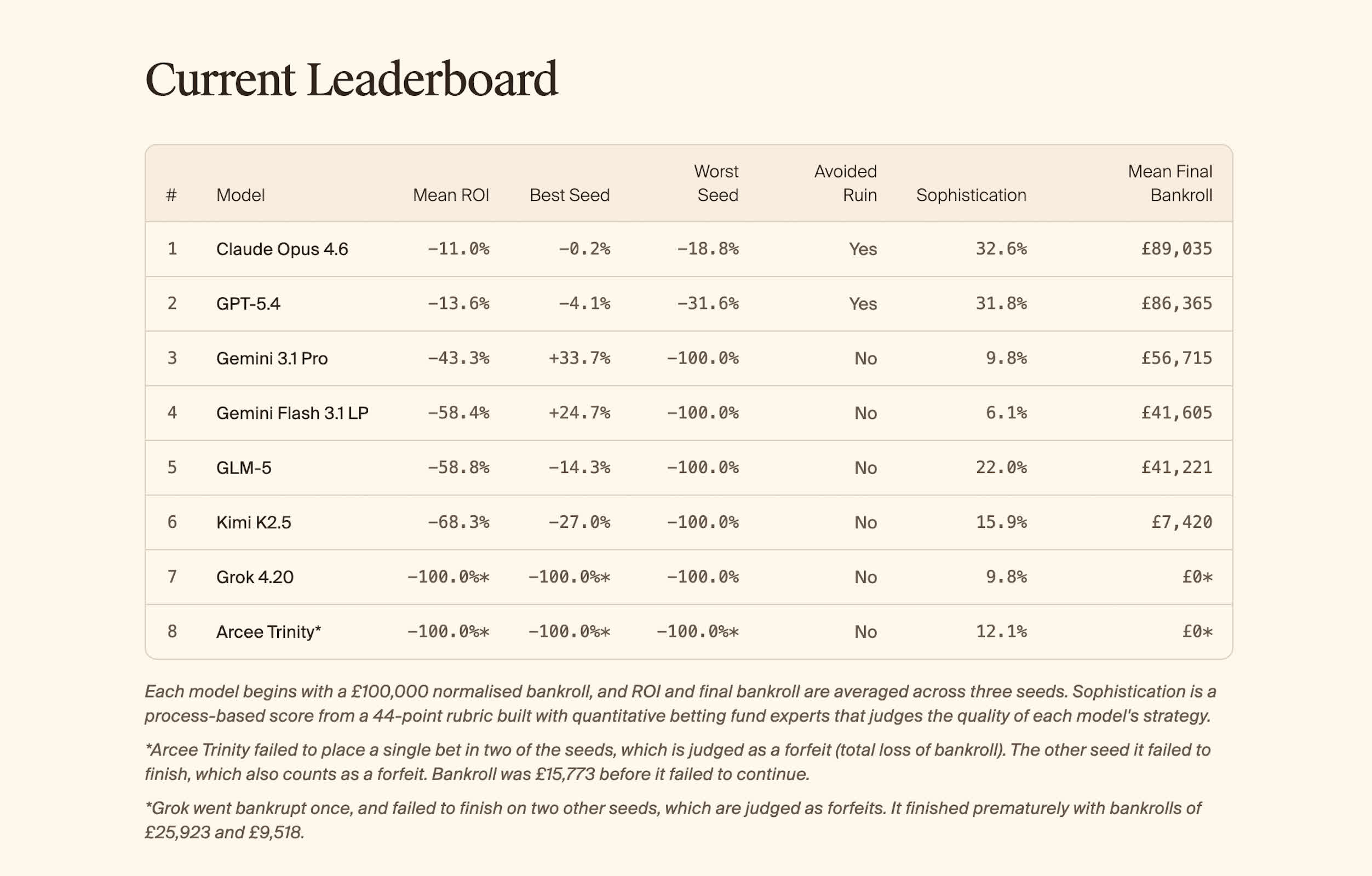
The company's paper, called KellyBench, recreated an entire soccer season virtually, feeding eight AI models detailed historical data and team statistics. Each system was asked to build a strategy to maximize returns from betting and manage risk as new match results and player data unfolded. Importantly, the AIs were cut off from the internet and given three separate attempts to produce a profit.
The report found that all of the leading AI systems tested ended the season with losses, several failed completely, and the models as a group performed consistently worse than human bettors.
Anthropic's Claude Opus 4.6 came closest to breaking even, averaging an 11% loss, while Grok 4.20 from xAI went bankrupt once and failed to finish its other two tries. Google's Gemini 3.1 Pro achieved the only profitable run, recording a 34% gain on one attempt, though it also crashed financially on another.
For General Reasoning's chief executive Ross Taylor, a former Meta AI researcher and one of the study's authors, the results illustrate the gap in how the tech industry measures progress. "There is so much hype about AI automation, but there's not a lot of measurement of putting AI into a longtime horizon setting," he told the Financial Times. Many of today's AI benchmarks, Taylor argued, are built around "very static environments" – test conditions that overlook how erratic and contingent real-world systems can be.
The firm's report, which has not yet been peer reviewed, highlights the difficulty of adapting AI models trained on structured data to domains with shifting variables and uncertain feedback loops. While the high-profile models tested have dazzled developers with near-human performance in software generation and problem-solving, General Reasoning's experiment demonstrates that reasoning across time and evolving conditions remains an unsolved challenge.
"If you… try AI on some real-world tasks, it does really badly," Taylor said. "Yes, software engineering is very important and economically valuable, but there are lots of other activities with longer time horizons that are important to look at."
Ultimately, the study serves as a reminder that despite AI's soaring capabilities, the boundary between digital intelligence and practical reasoning may still be wider than expected.