
In a nutshell: Artificial intelligence is starting to handle one of medicine's hardest tasks: making the right call when the data is incomplete. A new study in Science tested an OpenAI reasoning model on real clinical cases and found it could match and often outperform physicians when diagnosing patients and deciding on care. The work comes from researchers at Harvard Medical School and Beth Israel Deaconess Medical Center, who focused on how the system performs under real-world conditions rather than controlled benchmarks.
In one case, a patient came into the emergency department with a pulmonary embolism. The condition initially improved with treatment, then worsened. Doctors suspected the medication was failing. The AI model, using the same electronic health records available at the time, flagged a possible history of lupus – an autoimmune disease that can lead to heart inflammation. That turned out to be the correct explanation.
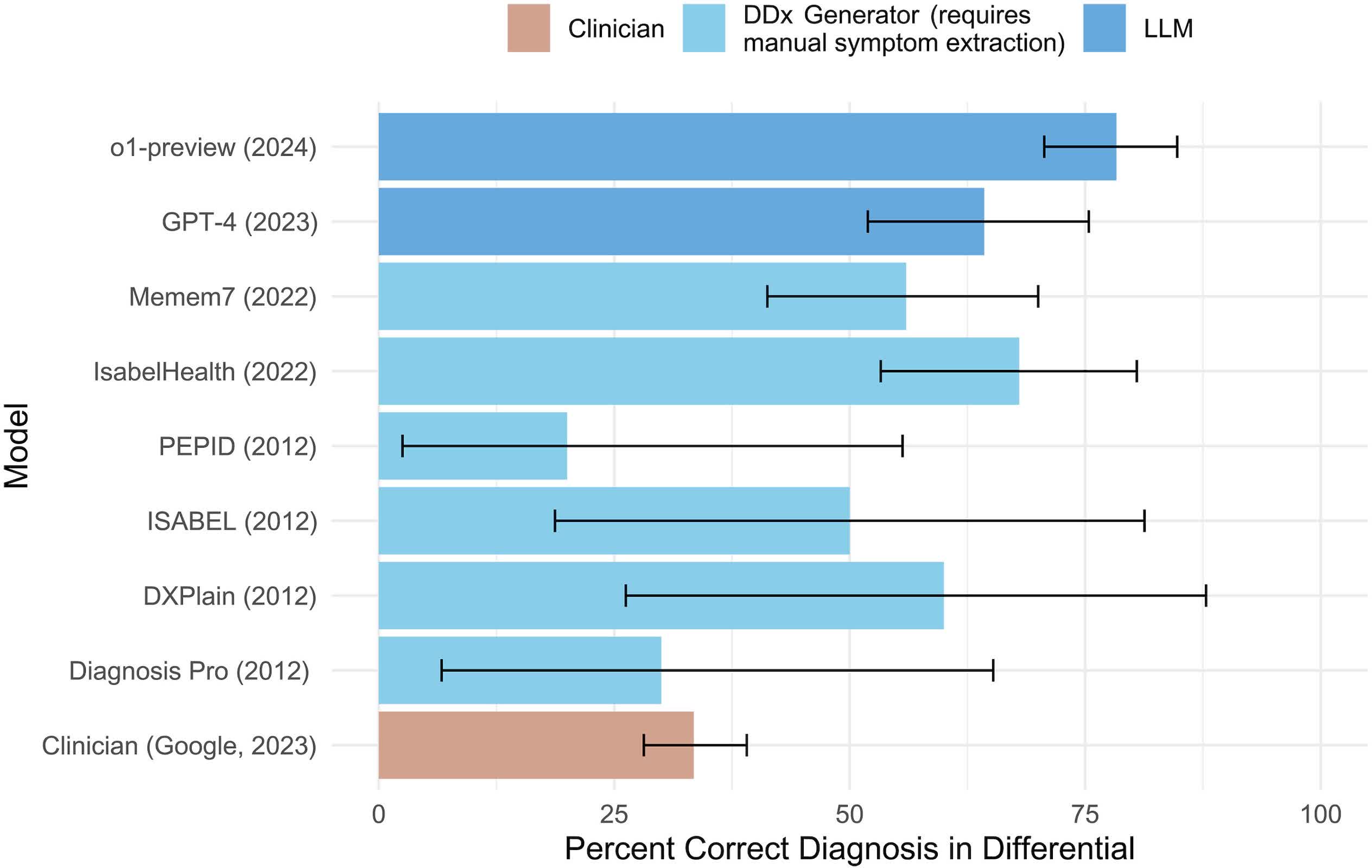
The researchers evaluated the model at multiple stages of care, from triage through hospital admission. At each step, they measured how well it could arrive at the right diagnosis using only the information available at that moment. Overall, the model outperformed two experienced physicians working under the same constraints.
"This is the big conclusion for me – it works with the messy real-world data of the emergency department," Dr. Adam Rodman, a clinical researcher at Beth Israel and one of the study authors, told NPR. "It works for making diagnoses in the real world."
The team also tested the model against clinical case reports from the New England Journal of Medicine and other standardized diagnostic challenges. These cases test complex diagnostic reasoning. The model again outperformed a large group of physicians used as a baseline.
"The model outperformed our very large physician baseline," said Raj Manrai, assistant professor of Biomedical Informatics at Harvard Medical School, who was also part of the study.
One important limitation is what the model didn't use. It relied entirely on text-based records. It did not process images, sounds, or nonverbal cues – inputs that are important in real clinical work. Even so, it handled uncertainty better than earlier systems, especially when building a differential diagnosis, where multiple possible conditions must be considered and narrowed down.
That marks a shift from previous generations of large language models, which often struggled when cases were ambiguous or incomplete.
Outside experts say the progress is real, but the path to deployment is unclear. "This paper is a beautiful summary of just how much things have improved," says Dr. David Reich, chief clinical officer for Mount Sinai Health System in New York, who was not involved in the work. "You have something which is quite accurate, possibly ready for prime time," he says. "Now the open question is how the heck do you introduce it into clinical workflows in ways that actually improve care?"
That gap between performance in testing and impact in practice is still unresolved. Emergency care is only one slice of the healthcare system, and the researchers note the model may not perform as well with long, complex hospital stays that involve more variables and evolving conditions.
The authors are also clear about what the study does not show. There is no evidence that AI should replace doctors. Instead, it points to a tool that could support clinical decision-making, especially in fast-moving environments where time and information are limited.
"I think it does mean that we're witnessing a really profound change in technology that will reshape medicine," Manrai said.
What comes next is harder: testing these systems in live clinical settings. That will require carefully designed trials to measure whether they actually improve outcomes, not just accuracy.
"It's a very challenging process to design these trials," Reich said, "but this study is a perfect call to action."