Facepalm: While embedded storage in modern smartphones has grown considerably, the software side of things still tends to make weird or outright incorrect calculations about available space. This problem persists in the upcoming Android release and is present in most third-party reskinned versions of the OS.

Both old and current versions of Android suffer from a peculiar bug concerning how the OS calculates storage space usage on mobile devices. Android specialist Mishaal Rahman, who uncovered this issue earlier this year, emphasized that even in the impending Android 14 release, the method Android uses to calculate space occupied by the OS "system" files remains fundamentally flawed.
The way Google's operating system calculates "system" files is utterly illogical, as explained on X. When new files are added to a smartphone's built-in storage, Android categorizes them as part of the "system" folder if they can't be placed in other categories like images, videos, documents, and so on. In simpler terms, Rahman pointed out that Android calculates the "system" component by merely subtracting the storage attributed to everything else from the total storage space that's currently in use.
Even user-created files that reside in the /data/media directory, which are unlikely to be system files at all, are classified by Android as part of the "system." Rahman showcased the bug by executing a shell command to generate a 3GB file filled with random data. Following the file's creation, the "System" category increased by 3GB.
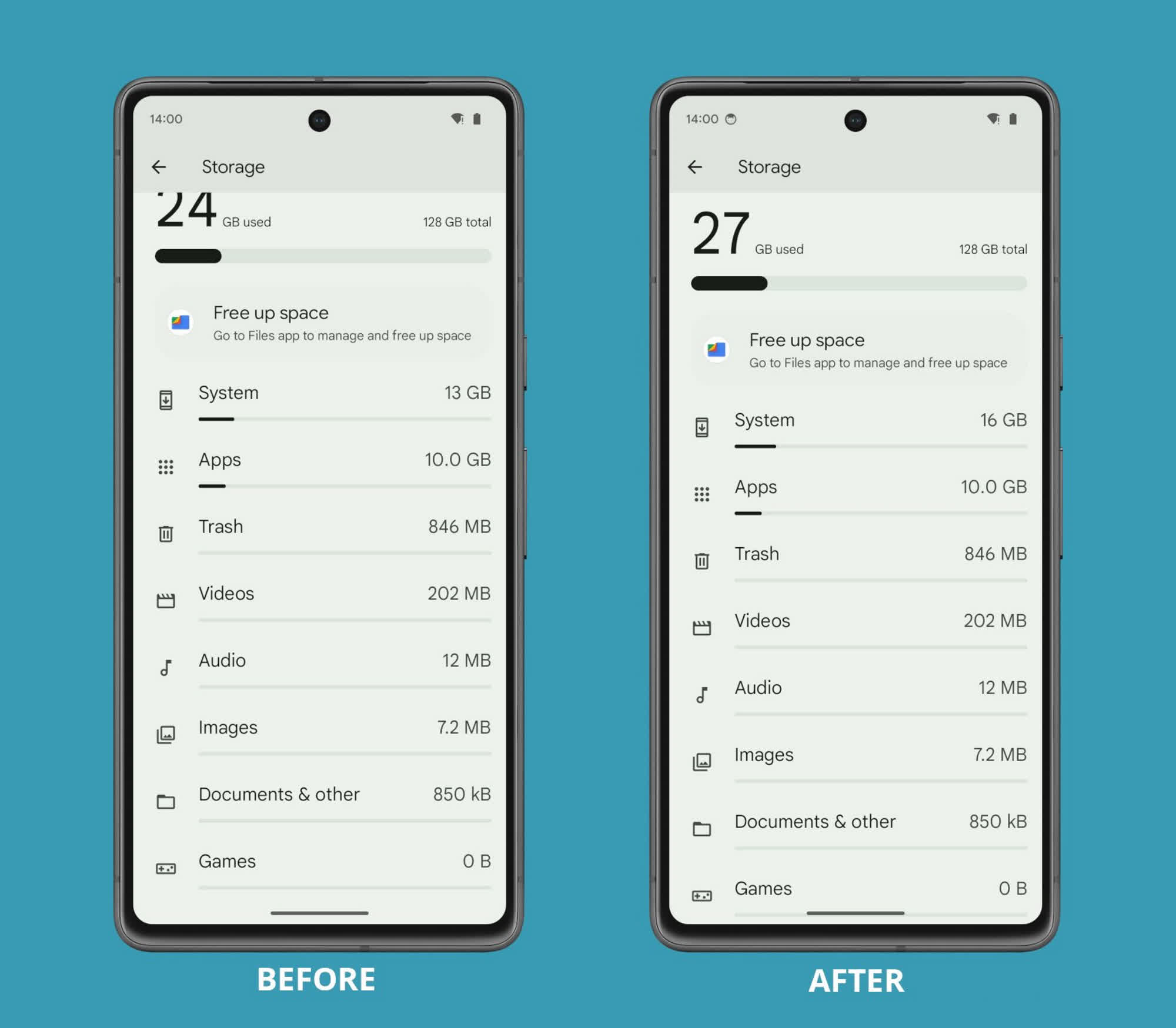
Besides incorrectly reporting the available space, the bug also impacts how the "Files" file explorer app calculates storage, likely because it employs the same flawed logic as the OS. Third-party "reskinned" versions of Android are also affected by the bug, with one notable exception: Samsung's One UI 6, according to Rahman, provides an accurate report of how files consume space on a mobile device.
Furthermore, as the journalist explained, Android has another issue with storage space reporting. Google employs the "gibibyte" unit for storage calculations, which equals 1024^3 bytes. In contrast, OEM manufacturers advertise storage capacity in "gigabytes," which equals 1000^3 bytes after the International Electrotechnical Commission (IEC) officially adopted the new prefix standards in 1998.
"Gibibytes" is the correct definition for representing the space that's actually available on a storage unit, but it can mislead users about the space their phone's manufacturer advertised. Rahman pointed out that this issue persists in Android 14, potentially leading users to unnecessarily perform factory reset procedures in an attempt to reclaim additional space that never actually existed.
https://www.techspot.com/news/100104-android-14-uses-nonsensical-logic-calculate-space-usage.html
