The big picture: Generative AI products are typically designed to easily create still images or text snippets by interpreting users' instructions. The company formerly known as Facebook wants to expand this capability to include audio and music content in the equation.

Meta recently launched AudioCraft, its framework to generate "high-quality," realistic audio and music, with an open-source license. The technology is designed to address a gap in the generative AI market, where audio creation has historically lagged behind. While some progress has already been made in this area, the company acknowledges that existing solutions are highly complicated, not very open, and not easily accessible for experimentation.
The AudioCraft framework is a PyTorch library for deep learning research on audio generation, comprising three main components: MusicGen, AudioGen, and EnCodec. According to Meta, MusicGen generates music from text-based user inputs, while AudioGen is designed to create audio effects. EnCodec, which was introduced in 2022, is a powerful encoding technology capable of "hypercompressing" audio streams.
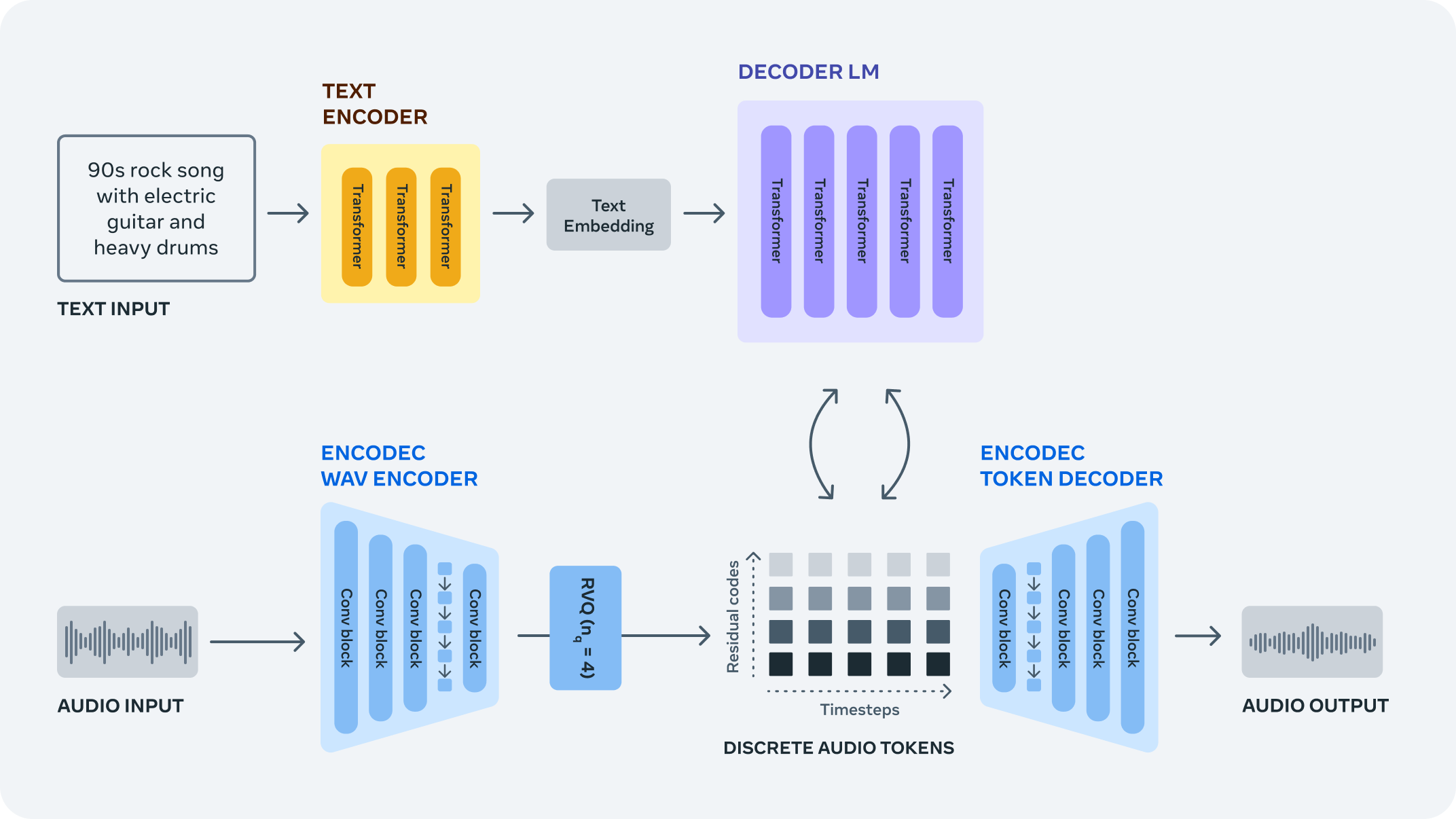
The MusicGen AI model can generate catchy tunes and songs from scratch. Meta is providing some examples generated from text prompts such as "Pop dance track with catchy melodies, tropical percussions, and upbeat rhythms, perfect for the beach," or "Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves."
AudioGen can be used to generate environmental background audio effects, such as a dog barking or a siren approaching and passing the listener. The open-source release of EnCodec is an improved version of the codec showcased in 2022, as it now allows for higher-quality music generation with fewer artifacts.
AudioCraft provides a simplified approach to audio generation, which has always been a challenge. Creating any kind of high-fidelity audio requires modeling complex signals and patterns at varying scales, the company explains. Music is the most challenging type of audio to generate, as it consists of local and long-range patterns. Previous models used symbolic representations like MIDI or piano rolls to generate content, Meta explains, but this approach falls short when trying to capture all the "expressive nuances and stylistic elements" found in music.
Meta states that MusicGen was trained on approximately 400,000 recordings along with text descriptions and metadata. The model absorbed 20,000 hours of music directly owned by the company or licensed specifically for this purpose. Compared to OpenAI and other generative models, Meta appears to be striving to avoid any licensing controversies or potential legal issues related to unethical training practices.
https://www.techspot.com/news/99659-audiocraft-open-source-audio-generative-ai-model-meta.html
")