In context: Watermarks are identifying patterns hidden within a piece of paper, an image, or other types of content. Manufacturers and providers can use it to detect counterfeit or piracy. Now, a Berlin-based company promises an even stronger watermarking system that works in the cloud.

German company castLabs recently introduced "single-frame forensic watermarking," a new, cloud-based way to easily and reliably identify piracy and IP theft. castLabs said that its novel approach allows the corporation to embed "tunable robustness level watermarks" in digital assets such as images, videos, documents, or any other type of digital file.
The system is presented as a way to protect copyrighted content in any possible scenario. Even in cases of distortion or obstruction, the new watermarking technology can seemingly work with just a single image to retrieve ID, IP addresses, session information and other useful detailed user data.
Single-frame forensic watermarking conceals vital information within a single frame of digital media, castLabs explained. The watermark can work in conjunction with other security measures such as Digital Rights Management (DRM) protections. The technology is split in two different parts, an embedder and an extractor.
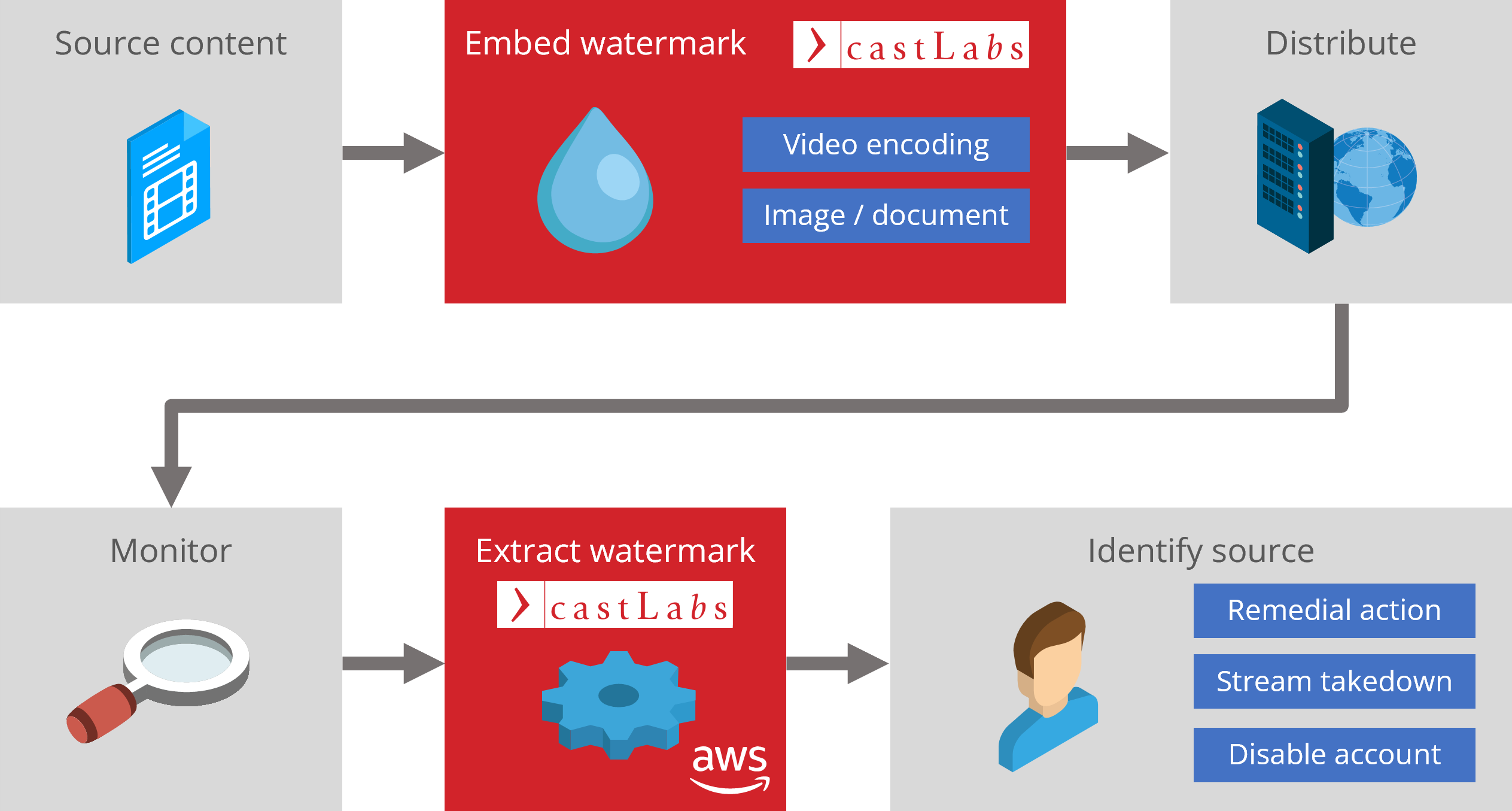
castLabs' unique algorithm embeds the watermark during the encoding process through the company's cloud-based Video Toolkit platform. The watermark is embedded server-side, castLabs revealed, with unique IDs that are "strategically" hidden within video frames or other visual digital assets. Its visibility can be "precisely" regulated to serve different use cases, seemingly providing a high survival level even in low-bitrate video and single image files.
The second part of the system, a cloud-based (AWS) extractor, can scan various areas in a video frame, a document, or an image, detecting the hidden watermark with what castLabs defines as a "remarkable resilience." This so-called "blind extraction" approach can retrieve a hidden pattern from a watermarked content when access to the original watermark is not available anymore.
castLabs is promoting its single-frame forensic watermarking solution to companies and organizations interested in taking "swift action" against content theft, as the extracted watermark can pinpoint the source of a leak within the supply chain. Furthermore, the system can provide "renewed deterrence," as potential infringers are aware that they can now be easily tracked, and "solid evidence" of content ownership to prove unauthorized uses in court.
https://www.techspot.com/news/99856-new-single-frame-watermark-technology-can-detect-piracy.html
