
A hot potato: Artificial Intelligence has advanced to the point where systems can now clone voices convincingly in real time, letting attackers mimic anyone during a live conversation. The breakthrough removes earlier limits that depended on prerecorded clips or slow processing, raising new cybersecurity and identity verification concerns.
Cybersecurity firm NCC Group has demonstrated that combining open-source AI tools with off-the-shelf hardware can generate real-time voice deepfakes with minimal latency. The technique, dubbed "deepfake vishing," uses AI models trained on samples of a target's voice to produce live impersonations that operators activate via a start button on a tailored web interface.
The process requires only modest computing power, though high-end graphics processing units improve results. The researchers ran the system on a laptop with an Nvidia RTX A1000 GPU – a lower-tier card – and achieved delays of only half a second. Audio samples show the system can produce convincing voice replicas even from poor-quality recordings, suggesting it could function with built-in microphones on everyday laptops and smartphones – making malicious use easier.
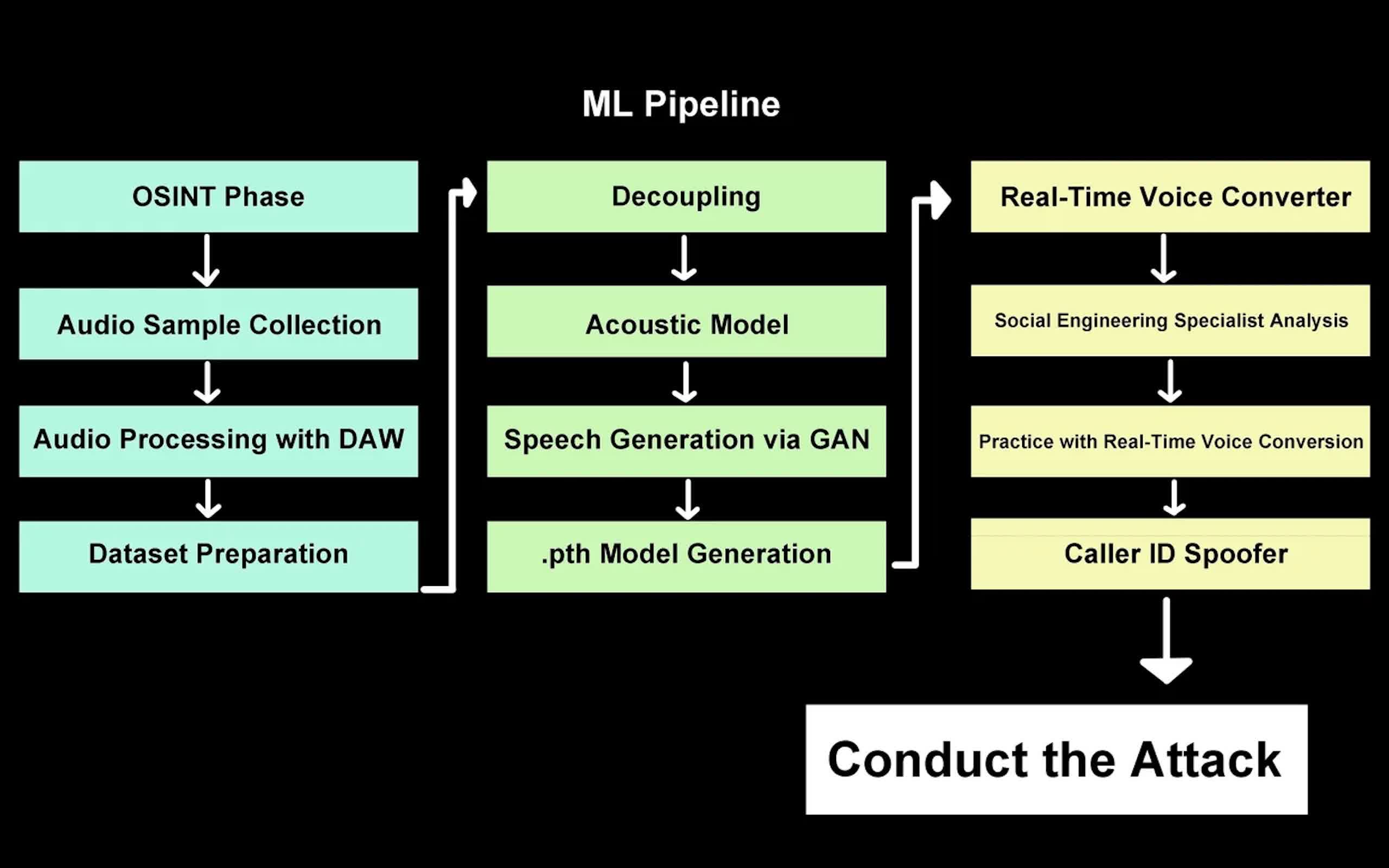
Previous voice deepfake services often required several minutes of training data and produced only prerecorded clips, making them less adaptable for live improvisational interactions. The ability to change voice in real time eliminates the natural pauses and hesitations that would otherwise reveal an impersonation attempt.
NCC Group Managing Security Consultant Pablo Alobera shared that during controlled testing with client consent, combining the real-time voice deepfake with caller ID spoofing successfully deceived targets in almost every attempt. The breakthrough greatly improves the speed and realism of voice forgery, exposing new risks even in ordinary phone calls.
While voice deepfakes have made notable progress, real-time video deepfakes have not yet reached the same level of sophistication. Recent viral examples use cutting-edge AI models such as Alibaba's WAN 2.2 Animate and Google's Gemini Flash 2.5 Image (nicknamed Nano Banana), which can digitally transplant virtually anyone into realistic video scenarios.
However, these systems still struggle to produce high-quality video in live settings and often exhibit inconsistencies in facial expressions, emotions, and speech synchronization. Trevor Wiseman, founder of the AI cybersecurity firm the Circuit, told IEEE Spectrum that mismatches between tone and facial cues remain giveaways even to casual observers.
The growing prevalence of these technologies has already led to tangible consequences. Wiseman points to a case where a company was fooled during the hiring process, sending a laptop to a fraudulent address after being duped by a video deepfake. Such cases show that voice and video calls cannot be relied on for authentication.
As AI-driven impersonation becomes more accessible, experts warn that new forms of verification will be essential. Wiseman advocates adopting unique, structured signals or codes – akin to the secret signs used in baseball games – to confirm identity during remote interactions unequivocally. Without such measures, individuals and organizations remain at risk of increasingly sophisticated social engineering attacks powered by AI-generated deepfakes.