Forward-looking: Audiobooks have gained popularity in recent years due to their accessibility, but recording them can be difficult and expensive. Researchers recently demonstrated an automated method using synthetic text-to-speech that solves numerous problems facing the technology and could enable ordinary users to generate audiobooks.

Readers can now listen to thousands of free classic literature audiobooks and other public-domain material through Project Gutenberg. Microsoft and MIT researchers created the collection by scanning the books with text-to-speech software that sounds natural and can adequately parse formatting.
The texts include works from Shakespeare, Agatha Christie, Jane Austen, Leonardo Da Vinci, and many others. Users can listen to them on the Internet Archive, Spotify, Apple Podcasts, and Google Podcasts. The code used to build the collection is available on GitHub.
Apple began selling audiobooks in January using automated text-to-speech technology. However, the venture was scrutinized by literary figures critical of Apple's commercial goals and voice actors whose work trained the company's AI. The Gutenberg approach might elicit a different reaction due to being open-source with no profit motive.
Project Gutenberg has spent decades assembling a library of free literature in text format to make it widely available for free, but audiobooks could make the material even more accessible. They're helpful for readers who are driving, multitasking, visually impaired, learning to read, or learning a new language.
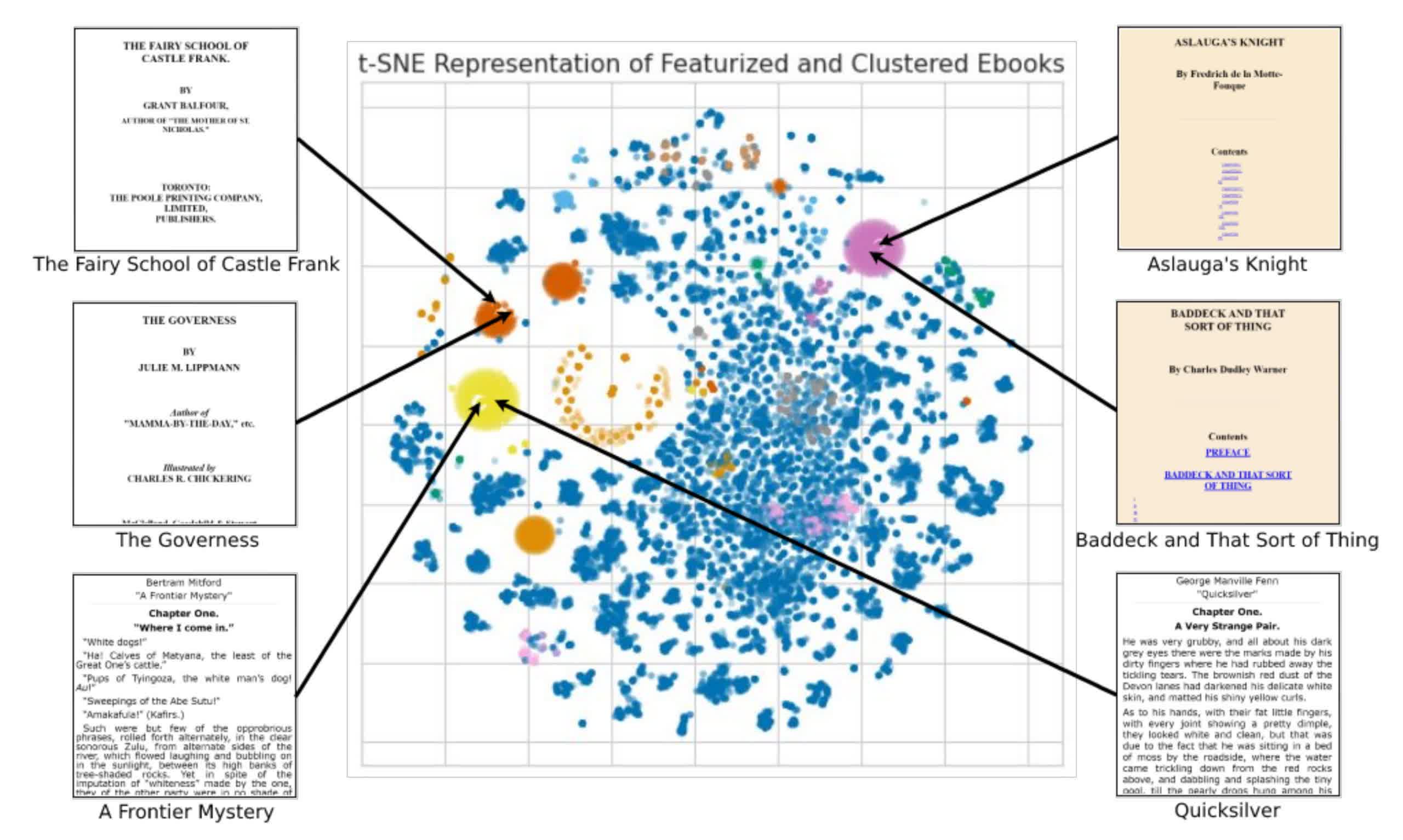
Creating an audiobook using traditional methods requires the time and money to pay someone to read an entire book aloud. It isn't economically worthwhile to manually record an audio version of every book worth reading. Text-to-speech is better suited for the Guttenberg Project. However, multiple obstacles faced the researchers' machine learning tools.
The first and most significant issue was determining which digital books the software could parse. Project Gutenberg collects its materials in multiple formats, and many of its files contain errors or imperfect scans. So, the researchers focused on books stored as HTML files and built a tool (pictured above) to discover which items displayed a similar format.
Another problem the researchers solved was ensuring the system knew which text to read or ignore. It addressed components such as tables of contents, page numbers, footnotes, tables, and other extraneous material.
Furthermore, the results need to sound close enough to natural human speech. The researchers focused on a vocal delivery best suited for nonfiction works and narration, but users can tweak the software to attempt dramatic readings.
The researchers plan to hold a demonstration allowing users to generate an audiobook with their voice. After recording a few lines to train the algorithm, each participant can hear a sample before enabling the software to read an entire book. They will also receive a copy of the audiobook via email. Users can optionally select from synthetic voices to customize each audiobook.
